Comparing Digital Video Downloads of Interlaced TV Shows

In the days of CRT monitors, TV shows used to be broadcast in interlaced mode, which is unsupported by modern flat-panel displays. All online streaming services and video stores provide progressive video, so they must deinterlace the data first. This article compares the deinterlacing strategies of Apple iTunes, Netflix, Microsoft Zune, Amazon VoD and Hulu by comparing their respective encodings of a Futurama episode.
Xbox Serial Number Statistics
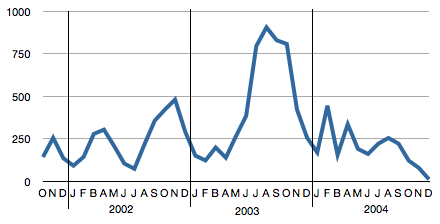
Slashdot had a story recently on how in 1942, the allies were able to estimate the number of German taks produced based on the serial numbers of the tanks. In 2010, a German hacker is doing the exact same thing with Xboxes. This article describes the generic approach, shows some results, and provides previously unreleased raw data of 14,000 Xbox serials so you can do your own statistics!
Windows Phone 7 & the Floppy Disk
I’m sure all users will immediately associate a Sony 3.5″ Floppy Disk with “save”. It’s not like the stock icon library also had an OK button.
The Intel 80376 – a Legacy-Free i386 (with a Twist!)
25 years after the introduction of the 32 bit Intel i386 CPU, all Intel compatibles still start up (and wake up!) in 16 bit stone-age mode, and they have to be switched into 32/64 bit mode to be usable.
Emu8080: an HTML5 App to Emulate a Complete CP/M Machine
by Stefan Tramm
HFS+ File System Analysis and Forensics with fileXray
Modern filesystems are highly optimized database systems that are a core function of modern operating systems. They allow concurrent access by many CPUs, they keep locality up and fragementation down, and they can recover from crashes guaranteeing consistent data structures.