In the series about the variants of the Commodore Peripheral Bus family, this article covers the common layer 4: The “Commodore DOS” interface to disk drives.
Commodore DOS is supported by all floppy disk and hard disk drives for the Commodore 8 bit family (such as the well-known 1541), independently of the connectors and byte transfer protocols on the lower layers of the protocol stack. The protocol specifies APIs for file access, for direct block access as well as for executing code on the device. Only a core set it supported by all devices though, while some devices have additional APIs.
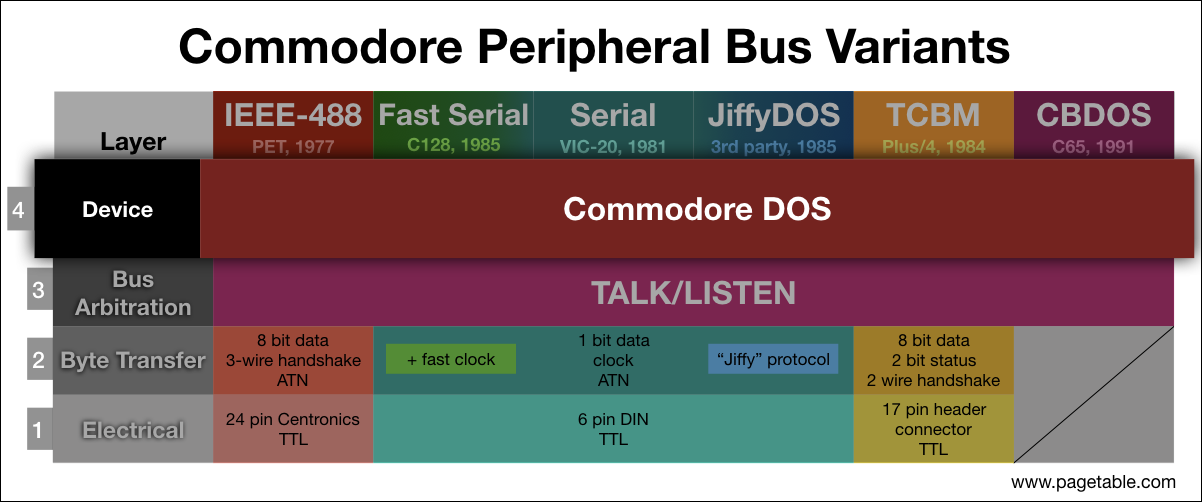
From a device’s point of view, the layer below, layer 3 (“TALK/LISTEN”) defines the following:
- A device has 32 channels (a.k.a. secondary addresses, 0-31).
- A channel (0-15) can be associated with a name and dissociated from it again.
- A device can send byte streams from channels.
- A device can receive byte streams into channels.
The Commodore DOS API defines the meaning of channel numbers, channel names and the data traveling over channels in the context of disk drives.
NOTE: I am releasing one part every week, at which time links will be added to the bullet points below. The articles will also be announced on my Twitter account @pagetable and my Mastodon account @pagetable@mastodon.social.
- Part 0: Overview and Introduction
- Part 1: IEEE-488 [PET/CBM Series; 1977]
- Part 2: The TALK/LISTEN Layer
- Part 3: The Commodore DOS Layer ← this article
- Part 4: Standard Serial (IEC) [VIC-20, C64; 1981]
- Part 5: TCBM [C16, C116, Plus/4; 1984]
- Part 6: JiffyDOS [1985] (coming soon)
- Part 7: Fast Serial [C128; 1986] (coming soon)
- Part 8: CBDOS [C65; 1991] (coming soon)
Feature Sets
Commodore DOS has been in existence since the Commodore 2040 drive from 1978, and new firmware code for Commodore DOS devices is being developed to this day. The API has gotten some extensions in the meantime, so while this article covers the complete API, it important to understand that not all APIs are supported by all devices.
| Feature | 2040 | 1541 | 1571/1581 | RAMDOS | CMD HD/FD | RAMLink | SD2IEC |
|---|---|---|---|---|---|---|---|
| Sequential files | yes | yes | yes | yes | yes | yes | yes |
| Relative files | no | yes | yes | yes | yes | yes | yes |
| Block access | yes | yes | yes | no | yes | yes | yes |
| Code execution | yes | yes | yes | no | yes | no1 | no |
| Burst commands | no | no | yes | no | yes | no | no |
| Time | no | no | no | no | yes | yes | yes |
| Partitions | no | no | no | no | yes | yes | yes |
| Subdirectories | no | no | no | no | yes | yes | yes |
(The 2040 is Commodore’s first (dual) disk drive. A ROM update to 2.0 later added relative file support. The 1541, 1571 and 1581 are the well-known C64 drives. RAMDOS is a RAM-disk application by Commodore that shipped with the “REU” RAM extender. Creative Micro Devices (CMD) made floppy disk and hard disk drives in the 1990s. SD2IEC is a modern floppy/hard drive replacement for Commodore computers with a Serial bus.)
Commodore drives up to the 1581 will be called “classic” devices further on.
The last device released by Commodore was the 1581 from 1987. CMD practically picked up this line of devices by releasing the HD and FD series devices with lots of added features – and APIs. These additions should be considered canonical.
Concepts
Commodore DOS calls a device (with its own primary address) connected to the bus a unit.
A unit can have one or more media1, a sequence of blocks whose numbering is independent of the other media. A medium usually contains a filesystem, but it can also be used for direct block access independently of any filesystem. These media are numbered, starting from “0”.
For devices that do not support partitions, a simple one-drive unit like the Commodore 1541 only has a single medium “0”. A dual-drive unit like the Commodore 8250 has two, named “0” and “1”, one for each disk drive. Reference manuals of these kinds of units call these numbers the drive number.
On devices that do support partitioning, each partition is a medium. The partitions are numbered starting with “1”, while “0” always points to the currently active partition. Reference manuals of these kinds of units call these numbers the partition number.
API Basics
Channels
Communication to Commodore DOS happens through 15 data channels and one command channel:
| Channel | Description |
|---|---|
| 0 | named (PRG read) |
| 1 | named (PRG write) |
| 2-14 | named |
| 15 | commands/status |
| 16-31 | illegal |
(While the underlying layers of the bus specifies channel numbers (secondary addresses) from 0 to 31, Commodore DOS does not support the numbers 16-31.)
Channels 0 to 14 need to be associated with a name and are used for the transfer of raw data like file and block contents. (0 and 1 are special-cased and will be discussed later.)
Channel 15 is a “meta” channel. When writing to it, the device interprets the byte stream as commands in a unified format. It either controls something about a specific data channel (out of band communication), or is a global command. When reading from it, the byte stream from the device is usually status information in a unified format, and sometimes raw response data to a command.
Commands
All commands are byte streams that are mostly ASCII, but with some binary arguments in some cases. All devices allow commands of up to 40 bytes in length, some allow more.
There are two different ways to send them:
They can be sent as a byte stream to channel 15, terminated by an EOI or UNLISTEN event2. The following BASIC code sends the command “I” to drive 8 this way:
OPEN 1,8,15
PRINT#1, "I";
CLOSE 1
(On layer 3, this will send LISTEN 8/SECOND 15/“I”/UNLISTEN.)
Alternatively, channel 15 can be opened as a named channel with the command as the name. This is not a real “OPEN” operation, and a closing would be a no-op. It just allows shorter code, e.g. in BASIC:
OPEN 1,8,15,"I"
CLOSE 1
(On layer 3, this will send LISTEN 8/OPEN 15/“I”/UNLISTEN/LISTEN 8/CLOSE 15/UNLISTEN.)
In both cases, commands that don’t contain binary arguments can also be terminated by the CR character.
Status
The status information that is sent from channel 15 is a CR-delimited3 ASCII-encoded string with a uniform encoding:
code,string,a,b[,c]
- code is a two-digit decimal error code.
- string is a short English-language version of the error code.
- a and b are two additional at least two-digit decimal numbers4 that depend on the type of error (“
00” if unused). - c is the single-digit decimal number drive that caused the status message. Devices with only a single drive don’t usually return this5.
A status code of 0 will return the string “00, OK,00,00” (or “00, OK,00,00,0” on dual-drive devices, assuming the last command was performed on drive 0).
Reading the status will clear it. So if the user keeps on reading the status channel, the device will keep sending “00, OK,00,00” messages.
The following BASIC program will read a single status message6:
10 OPEN 1,8,15
20 GET#1,A$: PRINT A$;: IF A$<>CHR$(13) GOTO 20
30 CLOSE 1
More info on error codes towards the end of this article.
APIs
There are several independent sets of API:
-
File Access API: This allows high-level access to files. No knowledge of the underlying data structures is needed. All devices support it.
-
Block Access API: This allows reading and writing individual logical blocks (256 bytes) of a medium. This can (optionally) be done ignorant of but still compatible with the filesystem’s metadata, i.e. to allow custom blocks to coexist with a healthy filesystem on a single medium. This API is optional. RAM-disks (Like RAMDOS) and network-backed devices don’t usually support it.
-
Code Execution API: This allows reading and writing memory in the unit’s interface controller, as well as executing code in its context. It is highly device-specific, but allows for implementing optimized or specialized code for existing functionality, or a device-side implementation of custom disk formats.
-
Burst API: This is a set of commands that mostly provides low-level access to the disk controller in order to allow reading and writing physical sectors – mostly to support foreign disk formats. The API also contains commands that initiate device memory and file access using the a variant of the “Serial” layer 2 (“Burst Transfer”).
-
Settings API: Later devices support a canonical set of global settings commands.
-
Clock API: Some devices keep track of time and can assign timestamp metadata to files. These devices allow reading and writing the current time using the clock API.
File Access API
Every medium has its own independent filesystem. A filesystem has a name, a two-character ID7, and contains an unsorted set of files. All files have a unique name as well as a file type, and have to be at least one byte in size8. Some devices maintain a last-changed timestamp with files, and some support nested subdirectories in order to group files.
Commodore DOS does not specify a maximum size for disk or file names, but the limit for all Commodore and CMD devices is 16 characters. There is also no specified character encoding: Names consist of 8 bit characters, and DOS does not interpret them. Names have very few limitations:
- The “
,” (comma), “:” (colon), “=” (equals) andCR(carriage return) characters are illegal in disk, file and directory names (because of the syntax of channel names and commands). - The “
/” (slash) character is illegal for directory names (because of the syntax of path specifiers). - The code
0xa0(Unicode/ISO 8859-1 non-breaking space, CBM-ASCII shifted SPACE) is illegal in file and directory names (it is used as the terminating character on disk).
There are two categories of files: sequential and relative files.
Sequential files only allow linear access, i.e. it is impossible to position the read or write pointer. They can be appended to though. There are three types of sequential files: SEQ, PRG and USR. They are treated the same by DOS, but the user convention is to store executable programs in PRG files and data into SEQ files.
Relative files (REL) have a fixed record size of 1 to 254 bytes and allow positioning the read/write pointer to any record and thus allow random access. (Early Commodore drives with DOS 1.x and some modern solutions don’t support this.)
While the interface to DOS often requires to specify the file type, it is not part of a file’s identifier, i.e. there can not be two files with the same name but just a different type.
Paths
Paths specify a subdirectory on a medium:
[medium][[/]/dirname[/…]/]
There can be an arbitrary number of dirname specifiers. Both the medium and the subdirectory names are optional. Omitting the medium will select medium 0, and omitting the subdirectory names will select the current subdirectory. Two slashes at the beginning mean the first directory name is relative to the root, otherwise it is relative to the current directory.
Examples:
- “” – the current directory on medium 0
- “
1” – the current directory on medium 1 - “
1/FOO/” – the subdirectoryFOOof the current directory on medium 1 - “
1//FOO/” – the subdirectoryFOOin the root on medium 1 - “
/FOO/” – the subdirectoryFOOof the current directory on medium 0 - “
1//FOO/BAR/” – the subdirectoryBARinside the subdirectoryFOOin the root of medium 1
On devices that do not support subdirectories, paths only consist of the (optional) medium name:
- “” – medium 0
- “
0” – medium 0 - “
1” – medium 1
Wildcards
Some APIs permit using wildcard characters:
* A question mark (“?”) matches any character.
* An asterisk (“*”) matches zero or more characters. On classic devices, characters in the pattern after the asterisk are ignored, so an asterisk can only match characters at the end of the name.
Opening Files
Files are read and written through named channels 0 through 14. Opening a named channel associates the channel with the filename. Closing it will dissociate the channel and, for files that were written to, make sure the file data on disk is consistent.
The following channel name syntax is used to open a file for reading or writing:
[[@][path]:]filename[,type[,mode]]
The core of the channel name is the name of the file to be accessed. If an existing file is opened, wildcards are allowed.
There are optional prefixes and suffixes.
-
The modifier flag “
@” specifies that the file is supposed to be overwritten, if it is opened for writing and it already exists9 – the default is to return an error. -
The path component allows specifing a medium and/or a sequence of subdirectory names. It defaults to medium 0 and the current path. The use of “
@”, a path, or both, requires adding a “:” character as a delimiter between the prefix and the filename. -
The file type is one of “
S” (SEQ), “P” (PRG), “U” (USR), or “L” (REL). If the type is omitted,PRGis assumed. -
The mode byte depends on the file type (see below).
(By specifying a path (even if empty, so it’s just the “:” prefix), it is possible to use filenames that start with “$” or “#”. These letters would otherwise indicate special named channels – see next sections.)
Sequential Files
For SEQ, PRG and USR, the following modes are possible:
R(read): Reading from the channel will return the file contents sequentially. The file pointer starts at the beginning of the file. When all bytes have been read, the unit signals this with anEOIcondition.M: (recovery read): This mode is a recovery feature that allows reading a file that is marked as inconsistent (i.e. written to but never closed) in the filesystem’s metadata. Normal read mode would refuse to open it.W(write): The file will be created (if it doesn’t exist or the “@” modifier has been specified), and writing to the channel will write the bytes into the file. The file has to be closed for it to be consistent. Creating a file and closing it without writing anything will result in a file that contains a singleCRcharacter10.A(append): Same as writing, but the file has to exist and the file pointer starts at the end of the file.
The default mode is “R”.
(Commodore DOS does not generally allow changing the file pointer on sequential files, but some modern solutions like SD2IEC allow the P command meant for relative files even in this case.)
Relative Files
For relative files, the mode character is actually a binary-encoded byte that specifies the record size. For creating a relative file, it must be specified, for opening an existing one, it can be omitted. Relative files are always open for reading and writing.
Positioning of the read/write pointer to a particular record is done by sending the “P” command on the command channel. The arguments are four binary-encoded bytes.
| Name | Syntax | Description |
|---|---|---|
| POSITION | P channel record_lo record_hi offset |
Set record index in REL file |
Relative files do not have to be closed for the data on disk to be consistent.
Channels 0 and 1
While channels 2 through 14 can be used to open a file in any mode, channels 0 and 1 are shortcuts that force the mode and set a default type of PRG:
- Channel 0 is the
LOADchannel: It forces an access mode of “read”. - Channel 1 is the
SAVEchannel: It forces an access mode of “write”.
Directory Listing
Reading the directory listing is done by associating channel 0 with a name starting with $ and reading from it. This is the syntax:
$[=T][[path]:][pattern[,…][={type|option}[,option, …]]]
Just using “$” as the name will return the complete contents of the current directory contents of medium 0. Specifying the path, followed by a colon, will override this. Additionally, one or more file name patterns can be appended to filter which directory entries are returned. Specifying “=” followed by a single-character file type specifier will only show files of a particular type. (Inconsistently, it’s “R” for “REL”, not “L” like in the case of opening a relative file.)
Devices that support time will allow a file listing that is amended with timestamp information, which can be requested using the “=T” modifier. In this case, any number of option arguments can be specified, which have the following meaning:
L: append long timestamp format; the default is shortened to fit an entry into 40 charactersN: do not append timestamp<timestamp: filter for files last changed before timestamp>timestamp: filter for files last changed after timestamp
The syntax of the timestamp argument works like this:
12/31/99 11:59 PM
(The year only has two digits. Consistent with GEOS, a year of “00” represents the year 2000. It is not specified what the cutoff year should be, but 1980 would make sense, so 80-99 would be 1980-1999, and 0-79 would be 2000-2079.)
The format of the data returned is tokenized Microsoft BASIC that can be displayed on-screen easily, but is a little tricky to parse.
Devices that support partitions also introduce the following syntax for listing partitions:
$=P[:*][=type]
The list can be filtered by partition type. CMD devices support the following types:
N: CMD native partition4: 1541 emulation partition (683 blocks)7: 1571 emulation partition (1366 blocks)8: 1581 emulation partition (3200 blocks, 1581-partition support)C: 1581 CP/M emulation partition (CMD HD only)
Filesystem Commands
There are many command-channel commands that deal with creating, fixing and modifying the filesystem. There is also a command that does a block-for-block disk copy for units with more than one drive.
| Name | Syntax | Description |
|---|---|---|
| INITIALIZE | I[medium] |
Force reading disk metadata |
| VALIDATE | V[medium] |
Re-build block availability map |
| NEW | N[medium]:name[,id[,format] |
Low-level or quick format |
| RENAME | R[path]:new_name=old_name |
Rename file |
| SCRATCH | S[path]:pattern[,…] |
Delete files |
| COPY | C[path_a]:target_name=[path_b]:source_name[,…] |
Copy/concatenate files |
| COPY | Cdst_medium=src_medium |
Copy all files between disk |
| DUPLICATE | D:dst_medium=src_medium |
Duplicate disk |
(Unless otherwise mentioned, arguments for all commands are ASCII.)
The INITIALIZE command is only useful on classic 5.25″ devices. These had trouble detecting the user swapping a disk, so this command makes sure the disk metadata cache is invalidated.
The VALIDATE command is a simple check-disk function that will make sure the “block availability map” is consistent with other on-disk data structures. It is recommended on a disk that contains a file that has not been closed after writing, but it needs to be avoided on disks that contain manually allocated blocks.
The NEW command will create a new filesystem. On removable media if an “ID” is specified, it will do a low-level format before. While most devices that support multiple physical formats will always format with the highest-density one11, CMD FD devices support the format agument (see the FD-2000 manual for a full discussion):
| format | Description |
|---|---|
81 |
double-density, 1581-compatible |
HDN |
high-density, one native partition |
EDN |
enhanced-density, one native partition |
(The Burst API allows more fine-grained formatting settings on supported devices.)
On units with multiple media, the COPY command can also copy files between media, while on all other units, it can only duplicate files. In either case, it can concatenate several files into one.
The DUPLICATE command and the COPY variant that copies all files are only supported on units with multiple drives, they do not work on partitions.
There are two more commands that got introduced by CMD:
| Name | Syntax | Description |
|---|---|---|
| LOCK | L[path]:name |
Toggle file write protect |
| WRITE PROTECT | W-{0|1} |
Set/unset device write protect |
| RENAME-HEADER | R-H[medium]:new_name |
Rename a filesystem |
Devices with partitioning support add the following commands:
| Name | Syntax | Description |
|---|---|---|
| CHANGE PARTITION | CP num |
Make a partition the default |
| GET PARTITION | GP num |
Get information about partition |
| RENAME-PARTITION | R-P:new_name=old_name |
Rename a partition |
(There is a variant of CHANGE PARTITION with the P character shifted (code 0xd0), which takes a binary-encoded partition number instead of an ASCII-encoded one.)
There are no commands to create or delete partitions. These functions have to be done through tools that know the internals of the specific device.
Devices with subdirectory support add the following:
| Name | Syntax | Description |
|---|---|---|
| CHANGE DIRECTORY | CD[path]:name |
Change the current sub-directory |
| CHANGE DIRECTORY | CD[medium]← |
Change sub-directory up |
| MAKE DIRECTORY | MD[path]:name |
Create a sub-directory |
| REMOVE DIRECTORY | RD[path]:name |
Delete a sub-directory |
The syntax to go up one level contains the “←” (left arrow) character, which is CBM-ASCII code 0x5f (underscore in US-ASCII).
Block Access API
Commodore DOS also allows accessing the disk on a lower level. The block API works with 256-byte-sized logical blocks that are identified by a logical track (1-255) and a logical sector (0-255)12.
The Buffer
In order to use the block API, a block-sized buffer has to be allocated inside the device by opening a channel (2-14) with the following name:
#[buffer_number]
The buffer number is only useful for a use case around code execution and will be covered later.
Without an explicit number, the next free buffer in the device’s RAM will be allocated. It will stay allocated until the channel is closed.
Reading from the channel gets a byte from the buffer, and writing to the channel puts a byte into the buffer. Every buffer comes with a “buffer pointer” that points to the next byte to be read or written. When creating a buffer, the buffer pointer is set to 1 instead of 0, so reading or writing would skip the first byte in the buffer. (The reason for this is the B-R/B-W API described later.)
The buffer pointer can be set to any position within the buffer with the B-P command.
All arguments in the buffer API are decimal ASCII values and can be separated by a space, a comma or a code 0x1d (ASCII “Group Separator”, CBM-ASCII “Cursor Right”). The command name and the first argument have to be separated by any of the above or a colon.
| Name | Syntax | Description |
|---|---|---|
| BUFFER-POINTER | B-P channel index |
Set r/w pointer within buffer |
Reading and Writing Blocks
The U1 and U2 commands allow reading a block into the buffer and writing the buffer into a block. The arguments are the channel number, the track and the sector. After reading a block, the buffer pointer is reset to 0, so that the 256 bytes of the bock can be read from the start.
Nevertheless, when uploading a complete block into the buffer and then writing it to disk, it is necessary to set the block pointer to 0 before sending any data because of the block pointer’s default value of 1.
| Name | Syntax | Description |
|---|---|---|
| U1/UA | U1 channel medium track sector |
Raw read of a block |
| U2/UB | U2 channel medium track sector |
Raw write of a block |
(On devices that support partitions, the medium number is ignored, and the current partition at the time of allocating the buffer is used instead.)
Block Availability Map Commands
The “B-A” and “B-F” commands allow marking a block as allocated or free in the “block availability map” (BAM). Allocating a block makes sure the filesystem won’t use it. The V (validate) command will re-build the BAM from the filesystem’s metadata and undo any “B-A” commands.
| Name | Syntax | Description |
|---|---|---|
| BLOCK-ALLOCATE | B-A medium medium track sector |
Allocate a block in the BAM |
| BLOCK-FREE | B-F medium medium track sector |
Free a block in the BAM |
Using the U1/U2 commands together with B-A and B-F allows using free blocks on the disk for custom use without interfering with the filesystem’s data structures. B-A will return the track and sector number of the next free block in case the one passed as an argument was already allocated. Together with the knowledge that the first block on disk is track 1, sector 0, it is possible to allocate blocks for custom use without any knowledge of the disk layout.
Similarly, a disk can be fully dumped by iterating over all tracks (starting with 1) and sectors (starting with 0) and skipping to sector 0 of the next track whenever an “ILLEGAL TRACK OR SECTOR” (66) error is encountered.
“Random Access Files”
The B-R (block read) and B-W (block write) commands have deceptive names and are part of a rarely used and deeply confusing feature: “Random Access Files”.
While sequential files only allow sequential access to the file’s data, and relative files restrict seeking within the file in record-size steps, the “Random Access File” API calls are meant to give the user a way to build files with arbitrary access patterns.
B-R and B-W are block read/write commands like U1/U2, but they assume a certain data format of the blocks: The first byte is the block’s buffer pointer. Before writing a block to disk, the current buffer pointer will be put into its first byte, signaling how many valid bytes are contained in the block. When reading, it marks the end of the buffer that cannot be read past13 (an EOI condition will be signaled). When reading with B-R, the buffer pointer is set to 1, so that the first byte of the payload will be read first.
| Name | Syntax | Description |
|---|---|---|
| BLOCK-READ | B-R channel medium track sector |
Read block |
| BLOCK-WRITE | B-W channel medium track sector |
Write block |
(As with U1/U2, the medium number is ignored on devices that support partitioning.)
Code Execution API
The code execution API provides all the tools to change the detailed behavior of a device as far as replacing the code that runs on it. Of course, code that uses these APIs is completely specific to one kind of device.
Allocating Specific Buffers
Specifying a number after the “#” character in the channel name will allocate the buffer with the specified number. This practically allocates a specific memory area in the device. This is the mapping on a 1541, for example:
| Buffer | Memory Area |
|---|---|
| 0 | $0300–$03ff |
| 1 | $0400–$04ff |
| 2 | $0500–$05ff |
| 3 | $0600–$06ff |
| 4 | $0700–$07ff |
On a 1541, buffer 2, which is located from $0500 to $05ff in RAM, is the designated “user buffer”. which is most likely to not be used by the device’s operating system.
Block Execute
With an explicit buffer allocated, one can have the device read a block into the buffer and execute it (by calling the base address) using the B-E command:
| Name | Syntax | Description |
|---|---|---|
| BLOCK-EXECUTE | B-E channel medium track sector |
Load and execute a block |
The code will run in the context of the “interface CPU”. (Some older Commodore devices had two CPUs, one for the Commodore Peripheral Bus interface, and one as the disk controller.) This CPU is usually a 6502 derivative, but executing code is highly device-specific in any case.
The operating system’s code will resume after the executed code returns.
Memory Commands
The memory commands allow reading and writing device memory as well as executing code at an arbitrary location.
The resulting bytes from the “M-R” command will be delivered through channel 15 in place of the status string.
The arguments are binary-encoded bytes.
| Name | Syntax | Description |
|---|---|---|
| MEMORY-WRITE | M-W addr_lo addr_hi count data |
Write RAM |
| MEMORY-READ | M-R addr_lo addr_hi [count] |
Read RAM |
| MEMORY-EXECUTE | M-E addr_lo addr_hi |
Execute code |
The M-W is subject to the same length restrictions as any command, so on most devices, it is limitied to writing 34 bytes at a time.
The count parameter of the M-R command is optional. If it is ommitted, a count of 1 is assumed.14
M-R and M-W allow accessing the operating system’s internal data structures, for example. The combination of M-W and M-E can be used to upload code from the computer and execute it. In case the drive’s operating system does not completely get taken over, it is advisable to allocate a specific buffer before uploading code, so that the operating system won’t overwrite the new code.
USER Commands
The USER commands are meant to give the user a compact command interface that calls uploaded code or code in expansion ROM (if available).
The commands U1 to U9 and U: (and their synonyms UA to UJ) execute code through a jump table. There is a default jump table that can be replaced using a device-specific M-W command, and reset to the default using U0.
| Name | Syntax | Description |
|---|---|---|
| U0 | U0 |
Init user vectors |
| U1-U2/UA-UB | (see above) | Raw read/write of a block |
| U3-U8/UC-UH | U3 – U8 |
Execute in user buffer or expansion ROM |
| U9/UI | UI |
Soft RESET (NMI) |
| U:/UJ | UJ |
Hard RESET |
For historical reasons15, the default jump table contains the already discussed U1 and U2 commands for reading and writing blocks. U3 to U8 jump into some useful device-specific locations. On most devices, all these jumps point into the user buffer, on some older devices, some jumps point into expansion ROM.
Here are the locations for the 1541:
| Command | Address |
|---|---|
U3/UC |
$0500 |
U4/UD |
$0503 |
U5/UE |
$0506 |
U6/UF |
$0509 |
U7/UG |
$050C |
U8/UH |
$050F |
The commands U9 and U: execute a soft and a hard reset, respectively. In both cases, the status will read back code 73, the power-on message, which is useful for detecting the type of device.
Utility Loader Command
The utility loader command instructs the unit to load a file into its RAM and execute it. The file has to follow a certain format and contains checksums16.
| Name | Syntax | Description |
|---|---|---|
| UTILITY LOADER | &[[path]:]name |
Load and execute program |
Burst API
The Burst API is a set of commands that mostly deal with low-level disk access, which were added to allow the user to read and write foreign MFM disks (1571, 1581, CMD FD), practically bypassing Commodore DOS.
All Burst commands start with with “U0”17, followed by one or more binary-encoded bytes that specify the command and its arguments.
The following table shows the commands and the binary encoding of their respective first byte. “_” characters don’t encode the command, but parts of the arguments.
| Code | Command | Description |
|---|---|---|
____000_ |
READ | Read logical or physical sectors |
____001_ |
WRITE | Write logical or physical sectors |
____010_ |
INQUIRE DISK | Detect new disk |
____011_ |
FORMAT | Format tracks |
____101_ |
QUERY DISK FORMAT | Detect disk format |
___0110_ |
INQUIRE STATUS | Detect disk change etc. |
___11101 |
DUMP TRACK CACHE BUFFER | Force cache write back |
___11111 |
FASTLOAD | Transfer file using Burst Serial protocol |
(For the complete command and return value encodings, refer to the 1581 or CMD FD manuals.)
All these commands require that all data transmission is done over a special layer 2 protocol called “Burst” Serial, which is only supported by “Fast Serial” devices. Part 7 of this series covers this protocol.
This explains the inclusion of the “FASTLOAD” command, which does not fit the topic of low-level disk access. The “Fast” Serial additions (as supported by the C128) can use a faster layer 2 protocol transparently to layers 3 and above, but the more specialized “Burst” Serial protocol (which was introduced together with Fast Serial) cannot be used transparently. Therefore the C128 KERNAL uses “FASTLOAD” to explicitly initiate a Burst transfer of the file if the device supports it.
There are also variants of the M-R and M-W commands that use Burst transfer:
| Name | Syntax | Description |
|---|---|---|
| BURST MEMORY-READ | U0>MR addr_hi count_hi |
Read RAM (Burst protocol) |
| BURST MEMORY-WRITE | U0>MW addr_hi count_hi |
Write RAM (Burst protocol) |
The Burst API breaks the layering of the protocol stack by marrying the low-level disk access commands to a specific byte transfer protocol18 – both were new features of the 1571.
The low-level disk access commands were added for reading and writing foreign-format 5.25″ disks, mostly for use with the CP/M operating system, which was really only useful on the 1571, and to some extent, the 3.5″ 1581. The CMD HD, for example, supported them for compatibility only. These commands should therefore be regarded as deprecated.
Nevertheless, the remaining “FASTLOAD” and “BURST MEMORY-READ/WRITE” commands are generally useful for devices with a Fast/Burst Serial layer 2.
Settings API
There are several commands that change global device settings that appeared in later devices.
These are the commands supported on all devices since the 1571[^96]:
| Name | Syntax | Description |
|---|---|---|
| USER | U0>S val |
Set sector interleave |
| USER | U0>R num |
Set number fo retries |
| USER | U0>T |
Test ROM checksum |
| USER | U0> pa |
Set unit primary address |
And some commands supported on all devices since the 1581:
| Name | Syntax | Description |
|---|---|---|
| USER | U0>B flag |
Enable/disable Fast Serial |
| USER | U0>V flag |
Enable/disable verify |
CMD devices added the following commands:
| Name | Syntax | Description |
|---|---|---|
| SWAP | S-{8|9|D} |
Change primary address |
| GET DISKCHANGE | G-D |
Query disk change (FD only) |
| SCSI COMMAND | S-C scsi_dev_num buf_ptr_lp buf_ptr_hi num_bytes |
Send SCSI Command (HD only) |
Real-Time Clock API
Some devices have a real-time clock that can be read and written in multiple formats.
| Name | Syntax | Description |
|---|---|---|
| TIME READ ASCII | T-RA |
Read Time/Date (ASCII) |
| TIME WRITE ASCII | T-WA dow mo/da/yr hr:mi:se ampm |
Write Time/Date (ASCII) |
| TIME READ DECIMAL | T-RD |
Read Time/Date (Decimal) |
| TIME WRITE DECIMAL | T-WD b0 b1 b2 b3 b4 b5 b6 b7 |
Write Time/Date (Decimal) |
| TIME READ BCD | T-RB |
Read Time/Date (BCD) |
| TIME WRITE BCD | T-WB b0 b1 b2 b3 b4 b5 b6 b7 b8 |
Write Time/Date (BCD) |
| TIME READ ISO | T-RI |
Read Time/Date (ISO) |
| TIME WRITE ISO | T-WI yyyy-mm-ddThh:mm:ss dow |
Write Time/Date (ISO) |
The ISO variant is only supported on the SD2IEC.
Family-Specific Features
There is a number of features that was only supported on one or a few devices and are not part of the canonical feature set.
1541 + 1571
For the 1541, the timing of the layer 2 Serial protocol was slowed down to support the C64’s unique timing properties. Since the 1541 replaced the 1540, it came with a mode to switch back to the faster VIC-20 Serial protocol19. This is only supported by the 1541 and 1571 series.
| Name | Syntax | Description |
|---|---|---|
| USER | UI{+|-} |
Use C64/VIC-20 Serial protocol |
1571
The following two commands are 1571-specific:
| Name | Syntax | Description |
|---|---|---|
| USER | U0>M flag |
Enable/disable 1541 emulation mode |
| USER | U0>H number |
Select head 0/1 |
1581
The 1581 has its own concept of “partitions” (which is also supported by CMD devices in 1581 emulation mode). A 1581 partition occupies a contiguous sequence of blocks and appears as a file of type CBM, but cannot be read or written as a file.
One use case for a 1581 partition is to reserve blocks for the block API that are safe from VALIDATE. But it is also possible to format the partition with a sub-filesystem20 (if the partition starts and ends at track boundaries and is at least 3 tracks in size). This way, partitions can even be nested.
| Name | Syntax | Description |
|---|---|---|
| PARTITION | /[medium][:name] |
Select partition |
| PARTITION | /[medium]:name,track sector count_lo count_hi ,C |
Create partition |
There is no syntax to access files in a different partition, it is only possible to change into partitions, and to change back to the root (by omitting the partition name).
C65
The disk drive built into the unreleased C65 supports the following additional commands:
| Name | Syntax | Description |
|---|---|---|
| FILE LOCK | F-L[path]:name[,…] |
Enable file write-protect |
| FILE UNLOCK | F-U[path]:name[,…] |
Disable file write-protect |
| FILE RESTORE | F-R[path]:name[,…] |
Restore a deleted file |
| BLOCK-STATUS | B-S channel medium track sector |
Check if block is allocated |
| USER | U0>Dval |
Set directory sector interleave |
| USER | U0>Lflag |
Large REL file support on/off |
Status Codes
Finally, here is some more information on the status codes and messages the unit sends through the command channel.
The first decimal digit encodes the category of the error.
| First Digit | Description |
|---|---|
| 0, 1 | No error, informational only |
| 2 | Physical disk error |
| 3 | Error parsing the command |
| 4 | Controller error (CMD addition) |
| 5 | Relative file related error |
| 6 | File error |
| 7 | Generic disk or device error |
| 8, 9 | unused |
The full list of error messages can be found in practically every disk drive users manual, here are just some examples:
00, OK,00,00: There was no error.01, FILES SCRATCHED,03,00: Informational: 3 files have been deleted (“scratched”).23,READ ERROR,18,00: There was a checksum error when trying to read track 18, sector 0.31,SYNTAX ERROR,00,00: The command sent was not understood.51,OVERFLOW IN RECORD,00,00: More data was written into a REL file record than fits.65,NO BLOCK,17,01: When trying to allocate a block using theB-Acommand, the given block was already allocated. Track 17, sector 1 is the next free block.66,ILLEGAL TRACK OR SECTOR,99,00: A user command referenced track 99, sector 00, which does not exist.73,CBM DOS V2.6 1541,00,00: This status is returned after the RESET of a device (and after the command “UI”). The actual message is specific to the device and can be used to detect the type and sometimes the ROM version21.
Note that the strings are meant for the user and not necessarily consistent between devices. A program should only ever interpret the status codes and its arguments.
Next Up
Part 4 of the series of articles on the Commodore Peripheral Bus family will cover Standard Serial (IEC).
This article series is an Open Source project. Corrections, clarifications and additions are highly appreciated. I will regularly update the articles from the repository at https://github.com/mist64/cbmbus_doc.
References
- Schramm, K.: Die Floppy 1541. Haar bei München: Markt-und-Technik-Verlag, 1985. ISBN 3-89090-098-4
- Neufeld, Gerald G.: Inside Commodore DOS. Northridge, Calif: Datamost, 1985. ISBN 0-8359-3091-2.
- 1541 Tricks
- VC 1541 Floppy Disk Bedienungshandbuch
- COMMODORE 1541 DISK DRIVE USER’S GUIDE, 1541d10a.txt
- COMMODORE 1571 Disk Drive User’s Guide, 1571-users-manual-1.0.txt
- COMMODORE 1581 Disk Drive User’s Guide, 1581-manual.txt
- C64DX SYSTEM SPECIFICATION
- Herne’s 1571 Disk Drive Guides: Burst Mode Commands
- Manual for CBM 8061 8″ disk drive
- CBM D9060/D9090/8250/8050/4040/4031 Bedienungshandbuch
- User’s Manual for CBM 5 1/4-inch Dual Floppy Disk Drives
- Commodore 1764 RAM Expansion Module User’s Guide
- Commodore RAMDOS Source
- CMD Hard Drive User’s Manual
- CMD FD Series User’s Manual
- CMD RAMLink User’s Manual
- FD Burst Command Instruction Set
- SD2IEC README
-
No other literature calls it media. In the Commodore context, they are drives (because they are actual drives with their own mechanics), and in the CMD context, they are partitions (because they are parts of one large drive). I have decided to introduce a common name for the concept, since the syntax for paths and commands does not make a distinction between the two.↩
-
The CMD RAMLink comes with an extra 64 KB of buffer RAM that can be read and written (to emulate the 1541/1571/1581 job queue), but the DOS runs on the computer’s CPU, so executing code on the device is not supported.↩
-
Commodore DOS breaks the layer 3 convention in this case. An
UNLISTENevent should not signal the termination of a byte stream, it should merely pause it.↩ -
In addition, devices signal EOI during the transmission of the
CRcharacter.↩ -
The two arguments are always 0-prefixed so they are at least two digits, but on devices with track or sector numbers above 99 (like the Commodore 8250 as well as CMD hard disks), they can be three digits.↩
-
The SFD-1001 is the exception to this: It is a single-drive device, but it has the exact same firmware as the dual-drive CBM 8250.↩
-
Instead of checking for
CR, it is also possible to loop until the EOI condition:20 GET#1,A$: PRINT A$;: IF ST<>64 GOTO 20↩ -
On classic 5,25″ devices, the user is supposed to make sure that disks have unique IDs. These devices store a copy of the ID with every sector on disk in order to detect disk changes more reliably.↩
-
This is a limitation of the layer 2 protocol: It is impossible for a device to send a 0-byte stream of bytes.↩
-
All single-drive Commodore devices except the 1571 (revision 5 ROM only), 1541-C, 1541-II and 1581 have a bug that can currupt the filesystem when using the overwrite feature.↩
-
Again, this is because of a limitation of the layer 2 protocol when reading the file. In addition, all Commodore drives have a bug where a file that contains only one or two bytes will read back four bytes, i.e. with added garbage. CMD drives do not have this bug.↩
-
The SFD-1001 and the 8250 are double-sided drives that can read and write single-sided disks (formatted by a 8050), but formatting a disk only supports double-sided mode. The same is true for the 1571 in native mode, which can read and write single-sided 1541 disks, but will always format double-sided disks – although the 1571 can format single-sided disks while in 1541 emulation mode.↩
-
On disks that do not use Commodore’s native “GCR” bit encoding (e.g. CBM 8280, D9060/D9090, 1581, the C65 drive and all drives by CMD), the physical layout does not match the logical layout, i.e. the medium may have a different sector size or track/sector(/head) numbering. On the CMD HD, the track and sector numbers are interpreted as a linear block address, and the constraint of 255 tracks and 256 sectors of 256 bytes limits the maximum partition size to just under 16 MB.↩
-
Many sources describe the “
B-R” and “B-W” commands as buggy because their behavior didn’t seem to make sense and the explanation seemed to have been missing from common forms of documentation. Where they are documented, they are called the “random access files” commands, for a third type of file (next to sequential and relative) that was based on the user keeping track of allocation and linking, but using the “first byte holds block pointer” format provided by these commands.↩ -
The
M-Rcommand has a bug on some devices: With oneM-Rcommand, you cannot cross a page boundary! That is, reading $20 from something like $03F0 will not succeed. That because the ROM functions for handling buffers always assume that a buffer does not cross a page boundary, so they do not take the high byte into account at all. But forM-R, this assumption is only true if the user knows about this restriction and makes sure he will never violate it.↩ -
U1andU2were added in a firmware update to the Commodore 4040 drive because of bugs inB-RandB-Win version 2.1. They were probably added asUSERcommands as opposed to proper commands (or fixing the broken commands) in order to keep the changes to the new ROM version contained to one ROM chip. Then later drives retained this feature for compatibility.↩ -
The feature has existed in all Commodore drives since the release of the 1540, but they only started documenting it with the 1551 drive, and never documented the actual file format or the algorithm for the required checksum. The 1540, early 1541 drives, the 8250/8050/4040 with DOS V2.7 as well as the D9060/D9090 hard disks supported the also undocumented “boot clip”: a device that grounds certain pins on the data connector and will force the unit to execute the first file on disk (“power-on diag sense loader”). All this hints at this mostly being a feature that was used in-house.↩
-
The 1571 aimed to be perfectly backwards-compatible with the 1541, so in order to keep the ROM layout as close to the 1541’s as possible, all added commands were added as sub-commands to
U0, which kept the new code contained behind a single vector.↩ -
The CMD RAMLink is compatible with as much of Commodore DOS as possible, but cannot support the Burst API, because it is not connected through a Commodore Serial bus.↩
-
The command was piggy-backed onto
UIin order to keep the changes between the 1540 and the 1541 contained to the second ROM chip.↩ -
Commodore calls them sub-directories, not to be confused with CMD-style subdirectories.↩
-
The version is sometimes more of a compatibility level though and hints at the supported features. These strings are too inconsistent between devices for parsing, so in practice, the whole string has to be compared for detecting a particular device.↩
Small correction: Secondary addresses 0 and 1 use PRG as the default file type, but it is not forced – you can still override them in the file name. The access mode is forced though.
Thanks. The correction has been applied to the article; a commit with credits has been added to the GitHub repo.
I want to comment on some things of your series.
First of all, reading the error message: I always use a loop which is based on ST instead of the character of A$, like:
10 OPEN 1,8,15
20 GET#1,A$:PRINT A$;:IF ST64 GOTO 20
30 CLOSE 1
Why? The ST of 64 signals an EOI. Thus, we can be sure that the channel has been read completely.
Coincidentially, the last byte, when an EOI is signalled, as a CR. However, from my understand, this is not by contract, although the floppy actually behaves this way.
Channels 0 and 1:
You say that these channels force a type of PRG and an access mode of “read” or “write”, respectively.
That is not completely true. They give the default of type “PRG”, but they do not force it.
So, you can also load USR or SEQ files by using a command like
LOAD “FILENAME,S”,8
or
SAVE “FILENAME,U”,8
(Oh, before sending it, I see that Ingo Korb also commented this)
Memory commands
The M-W has a restriction of the maximum number of bytes it can write. On a 2031/154x/157x, this is at most 34 byte, as the input buffer is 41 byte and we need an additional space for “M-W” (3 byte), the address low, high, and the number of bytes (3 byte), and the resulting CR (1 byte).
The count parameter of the M-R command is optional. If it is ommitted, a count of 1 is assumed.
The M-R command has a oddity (bug?) which I never found documented anywhere: With one M-R command, you cannot cross a page boundary! That is, reading $20 from something like $03F0 will not succeed. That because the ROM functions for handling buffers always assume that a buffer does not cross a page boundary, so they do not take the high byte into account at all. But for M-R, this assumption is only true if the user knows about this restriction and makes sure he will never violate it.
The commenting system ate my “less-than” and “greater-then” signs in the small basic program. ST is compared to being unequal to 64 there.
Thanks. The corrections have been applied to the article; a commit with credits has been added to the GitHub repo.
If I remember correctly, you can also open the file “$” (for read) on channels 2 and up. In that case, it reads the BAM and directory sectors, without converting to a LIST-able format.
Thanks for this. I was thinking about making a simple disc emulator for my PET and this really helps.
Amazing article. Thank you so much for taking the time.
Since you seem to have a very thorough knowledge of the C= serial bus, as well as CMD HDs, I wonder if you’ve ever seen this issue before.
When I first got my CMD HD, I spent several hours teaching myself how to get it to work in a very complex system I’d built. I ultimately got a somewhat rare parallel cable for it and hooked it up from a RAMlink directly to the drive. It works absolutely great this way, and fast.
However, whenever I try and eliminate the RAMlink and just use the IEC bus I run into trouble. For some reason when only in a serial port environment other drives on the chain have issues.
What happens is the HD drive will work fine, but other drives on the serial chain (like a 1581 disk drive) will stop being able to function properly. If I try and do a directory listing of the other drives, the computer will hit them and make their activity lights come on but will hang. I’ve made several adjustments to where devices are located in the chain and the HD *always* works but the other drives stop being able to read disks.
I’ve reached out to a couple other folks and I’ve heard some say they’ve seen this behavior before, too, but didn’t remember how they’d resolved it (way back when). Super strange. Have you seen this before, too? And if so, what did you do to fix it? It’s driving me nuts.