Final Cartridge III Calculator Easter Egg

The C64 extension cartridge Final Cartridge III contains a graphical user interface named “Desktop”. There are two easter egg messages hidden in the calculator (from the “Utilities” menu).
Commodore Disk Drive 1570/1571 Bedienungshandbuch [PDF]

Commodore Business Machines:
Commodore Disk Drive 1570/1571 Bedienungshandbuch
1985.
(164 pages, 27 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Commodore 128, das große BASIC-Buch [PDF]

Frank Kampow:
Das große BASIC-Buch zum Commodore 128
Düsseldorf: Data Becker, 1985.
ISBN 3-89011-114-9.
(466 pages, 40 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Commodore 128 Tips & Tricks [PDF]

Ralf Hornig, Tobias Weltner, Jens Trapp:
Commodore 128 Tips & Tricks
Düsseldorf: Data Becker, 1986.
ISBN 3-89011-097-5.
(450 pages, 40 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Trainingsbuch zu Textomat [PDF]

Dietmar Froitzheim:
Das Trainingsbuch zu TEXTOMAT
Düsseldorf: Data Becker, 1984.
ISBN 3-89011-031-2.
(222 pages, 19 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Trainingsbuch zum SIMON’s BASIC [PDF]

Axel Plenge, Norbert Szczepanowski:
Das Trainingsbuch zum SIMON’S BASIC
Düsseldorf: Data Becker, 1983.
ISBN 3-89011-009-6.
(394 pages, 70 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Statistikbuch zum Commodore 64 [PDF]

Werner Voß:
Das Statistikbuch zum Commodore 64
Düsseldorf: Data Becker, 1985.
ISBN 3-89011-102-5.
(468 pages, 33 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Schulbuch zum Commodore 64 [PDF]

Werner Voß:
Das Schulbuch zum Commodore 64
Düsseldorf: Data Becker, 1984.
ISBN 3-89011-019-3.
(354 pages, 21 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Grafikbuch zum Commodore 64 [PDF]

Axel Plenge:
Das Grafikbuch zum Commodore 64
Düsseldorf: Data Becker, 1984.
ISBN 3-89011-009-6.
(305 pages, 28 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Commodore-64-Spiele-Buch [PDF]

Owen Bishop:
Das Commodore-64-Spiele-Buch
Frankfurt/M.: Commodore, 1984. (Commodore-Sachbuchreihe, Bd. 4)
ISBN 3-89133-002-2.
(162 pages, 29 MB)
Aus dem Englischen übertragen von Gudrun Breiter. Originaltitel: The Commodore 64 Games Book – 21 Sensational Games (Granada Publishing, 1983).
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das Nikolaus-Heusler-Archiv
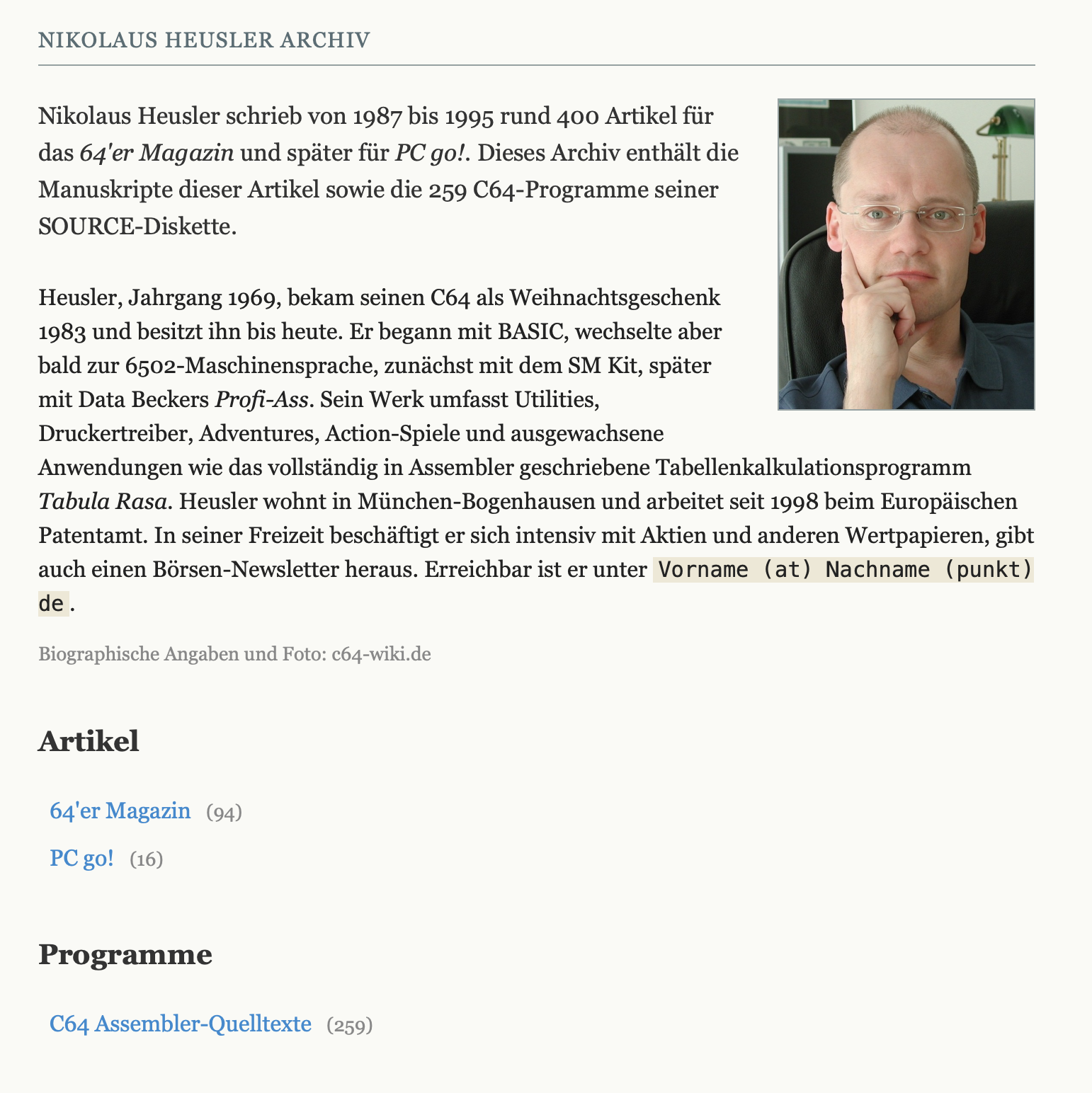
Nikolaus Heusler zählt zu den produktivsten Autoren des 64’er Magazins: hunderte Beiträge zwischen 1987 und 1995. Heusler, Jahrgang 1969, hatte seinen C64 zu Weihnachten 1983 bekommen; heute arbeitet er beim Europäischen Patentamt in München.
Running Adobe’s 1991 PostScript Interpreter in the Browser
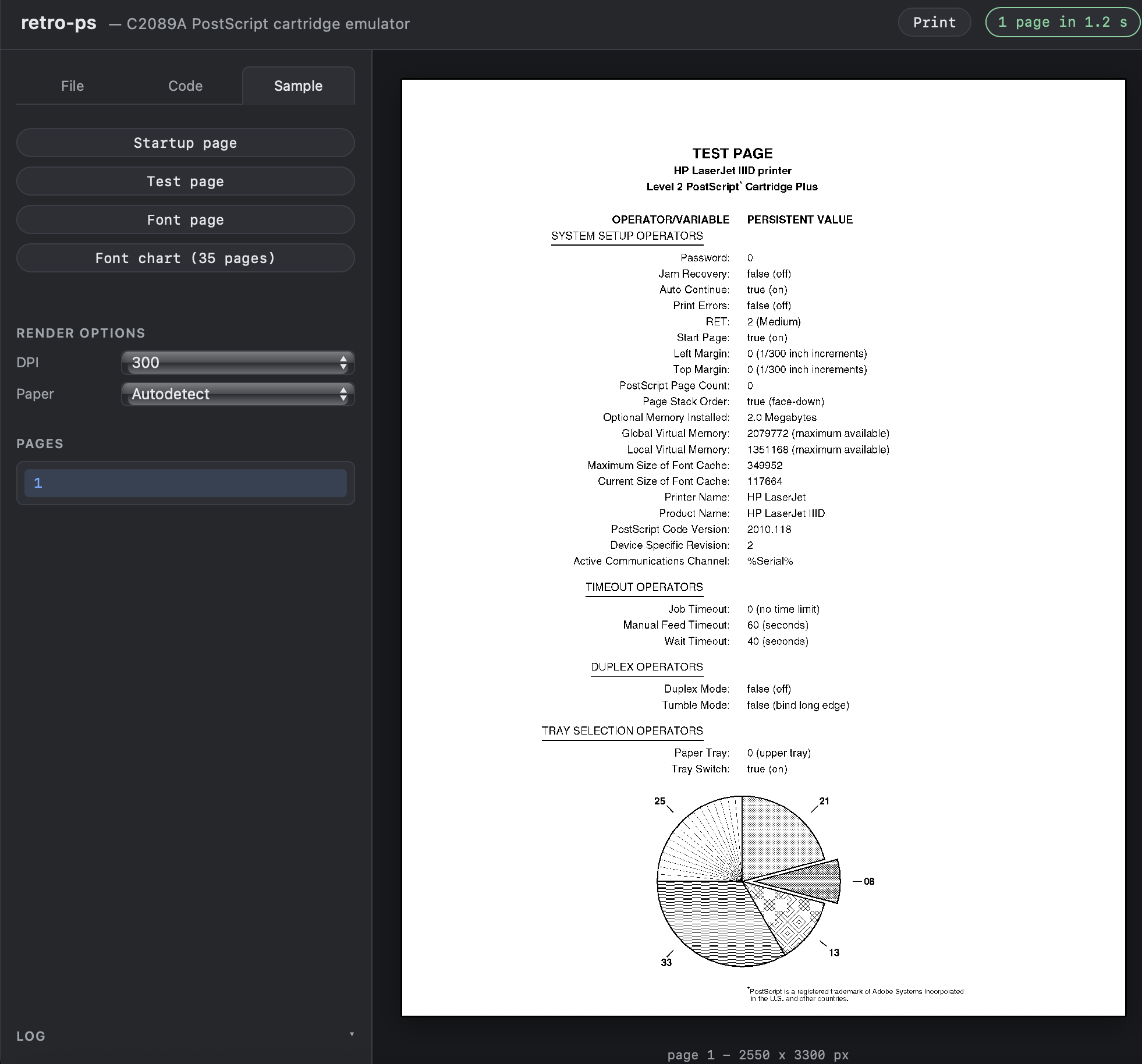
The HP C2089A “PostScript Cartridge Plus”, a 1991 add-on for the LaserJet II/III, adds PostScript Level 2 support through Adobe’s own reference interpreter (version 2010.118) on a 2 MB ROM.
PacificPage P·E PostScript Cartridge for HP LaserJet II/III

PostScript came to the desktop in 1985 with the Apple LaserWriter, and within a year or two several other companies had joined Adobe’s licensee list. HP was late — its own Adobe PostScript cartridge for the LaserJet II/III family didn’t ship until 1991.
Lohnsteuerjahresausgleich? Einkommensteuererklärung? Mein C 64 hilft mir dabei! [PDF]

Ilona Kwiatkowski, Peter Vogt:
Lohnsteuerjahresausgleich? Einkommensteuererklärung? Mein C 64 hilft mir dabei!
Heidelberg: Hüthig, 1985.
(204 pages, 16 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Einführung in CAD mit dem Commodore 64 [PDF]

Werner Heift:
Einführung in CAD mit dem Commodore 64
Düsseldorf: Data Becker, 1985.
ISBN 3-89011-067-3.
(322 pages, 18 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Das große Drucker-Buch [PDF]

Rolf Brückmann, Klaus Gerits, Thomas Wiens:
Das große Drucker-Buch
Düsseldorf: Data Becker, 1984.
ISBN 3-89011-020-7.
(392 pages, 26 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
Klaus Finke’s Commodore 64/128 GEOS Disk Collection
This is a collection of 111 Commodore 64/128 disk images from a box of CMD FD-2000 high-density floppy disks. The disks came from the estate of Klaus Finke (1945–2016), a GEOS community organizer from Suhl, Thuringia.
How the Final Cartridge III Freezer works
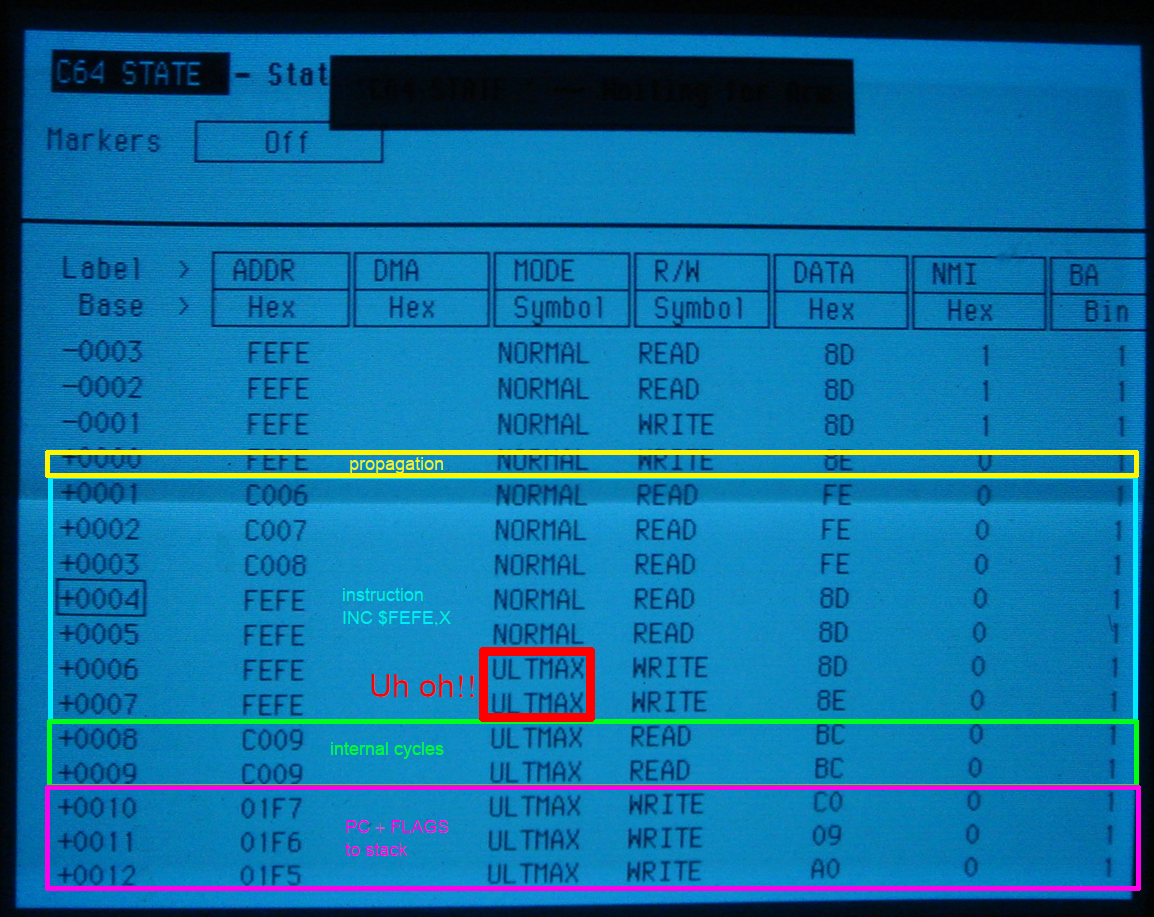
by Daniël Mantione
64 Tips & Tricks [PDF]

Michael Angerhausen, Lothar Englisch, Klaus Gerits, Frank Thrun:
64 Tips & Tricks
Düsseldorf: Data Becker, 1984. (4. erweiterte und überarbeitete Auflage)
ISBN 3-89011-001-0.
(386 pages, 26 MB)
Danke an Dirk Wagner für die Bereitstellung des Buchs.
6502 Illegal Opcodes in the Siemens PC 100 Assembly Manual (1980)

The 6502’s “illegal” opcodes were of intense interest to home computer enthusiasts, and analyses were published in various magazines. But one would have never expected a company like Siemens to document illegal opcodes in a programming manual from 1980.