In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses how its file format allows the app to efficiently edit documents hundreds of KB in size.
Article Series
- The Overlay System
- Screen Recovery
- Font Management
- Zero Page
- Copy Protection
- Localization
- File Format and Pagination ← this article
- Copy & Paste
- Keyboard Handling
Design
Writing a word processor, especially a WYSIWYG one, poses two core challenges:
- Memory Management: The whole document may not fit into memory. A small text file is easily dozens of KB, and a large one hundreds of KB, not counting inline images. The word processor needs a strategy to only keep the parts in memory that are currently needed.
- Pagination: WYSIWYG mans that the user will always see on which page, and where on that page the text that is currently being edited will appear when printing. This requires the word processor to layout the whole text up to the current position.
Memory Management
The natural approach to memory management is to only read a small part of the document into memory for viewing and editing. Once the user jumps to a different part of the document or writes enough text to fill the buffer, the current part has to be written to disk, and a different part has to be loaded into memory.
This is tricky with regular (“sequential”) files: When writing a part of the document back to disk, the new version is generally a different size than the part that it replaces. This means that the remainder of the document has to be moved. In the worst case, this requires making a complete copy of the document and temporarily taking up twice the space on disk.
GEOS has the concept of a VLIR file, which is a collection of up to 127 “sub-files”, called records, numbered 0 to 126. The geoWrite application itself consists of several such records for its own code, which are paged in based on which functionality is being used. Similarly, geoWrite documents are VLIR files containing multiple records of no more than 7 KB – this is how much memory is left on a 64 KB RAM system after accounting for the operating system and the geoWrite application.
In the generic case, the word processor can then just read a single record from disk into memory, have the user edit it, and write the record back to disk. All other records remain unchanged.
A simple approach for dividing up the document would be to just cut it into 7 KB parts. If text is added to the middle of the document, and the record overflows 7 KB, it will have to be divided into two, and all subsequent records have to be moved up. If two consecutive parts are less than 7 KB together, they can be combined, and subsequent records have to be moved down. Moving records really just means renaming them and is therefore cheap.
The problem with dividing up the document at fixed limits is that the point where text continues from one record to the next may be anywhere. Therefore, a single sentence on the screen might come from two different records, and moving the mouse across this invisible line will cause slow (and surprising!) disk access. It’s even worse when performing an operation on selected text that spans two records, which may cause swapping in and out of parts multiple times.
Pagination
The other challenge is pagination. There is no information in the document on how to map a page number to a record, so if the user wants to jump to a specific page, the word processor would have to actively find out what part of the document will end up printed on that page. If the desired page is after the current one, all text from the current position on has to be paginated, i.e. put through the page layout logic until the point in the document is found that will be printed on the specified page. If the desired page is before the current one, the same logic would have to be done starting from the first page of the document.
To avoid redundant “re-pagination”, the calculated pagination information could be stored as metadata in the file. For every page, this would be the combination of record number and offset within the record to point to the first character of the page. If text is edited anywhere but at the end of the document, the remainder of the document has to be re-paginated, and the table has to be updated – this can be done lazily. Jumping within the document now only requires a table lookup.
geoWrite Strategy
geoWrite uses a combined strategy for memory management and pagination: It maps every page to exactly one record. The app reserves 7000 bytes of RAM for the currently edited page, which corresponds to just about one page fully filled with 9 pt text. Jumping to a different page is as simple as reading a different record – without requiring a separate page-to-record mapping table. And it also solves the other problem from before: Since a whole page is guaranteed to be in RAM, editing text within a page generally does not cause disk access.
Picking pages as the unit of editing does sound weird at first, because the separation into pages is such a transient property of a text document. After all, the very idea of a word processor (as opposed to a typewriter) is that the user can regard the document as just linear text without worrying about page breaks. When editing text, page boundaries change, and the whole document would have to be changed. This is true, but these re-layouts of the document are necessary when editing, no matter what strategy is used to cut the document into pieces.
Here is an overview of the properties of the two strategies, with the more desirable ones marked in bold:
| Max Size Records + Metadata | One Record per Page | |
|---|---|---|
| Jump to page | lookup, read record | read record |
| Add text in the middle | re-pagination | re-pagination & data copy |
| Surprising disk access | yes | no |
- Both strategies allow navigating the document efficiently.
- Adding text to the middle of the document always requires re-pagination of the following pages at some point. With the “one record per page” strategy, this also requires going through all following records and re-combining them according to the new page breaks.
- Generally, no edit operation within a single page will cause disk access with the “one record per page” strategy.
So it’s basically a tradeoff between repagination speed and editing performance, and geoWrite went for the latter.
File Format
Before we discuss when and how exactly a document is re-paginated with geoWrite, we have to dive into the exact file format.
geoWrite files are VLIR files. GEOS specifies a VLIR file as consisting of a 256 byte file header and up to 127 records of arbitrary lengths.
The file header of any GEOS document contains the file’s icon, type and creator, a comment, and optionally, type-specific metadata.
geoWrite stores 9 bytes of metadata at offset $89 for document-global properties:
| Offset | Size | Contents | Description |
|---|---|---|---|
| $89-$8A | Word | Start Page Number | Number of first page, usually 1 |
| $8B | Byte | Title/NLQ Flags | $80: has title page, $40: NLQ mode |
| $8C-$8D | Word | Header Height | Height of header in dots |
| $8E-$8F | Word | Footer Height | Height of footer in dots |
| $90-$91 | Word | Page Height | Page height in dots |
- The start page number can be set to numbers other than 1, to allow splitting a project into multiple document files with consistent page numbering.
- If the document has a title page, no header or footer will be printed onto the first page.
- In NLQ mode, the document will be printed by sending ASCII characters to the printer, using the printer’s built-in fonts. This changes the metrics calculation.
- Header and footer height are calculated from the header/footer text. These are cached values to allow page layouts without having to measure the height of the header and the footer.
- The page height is generally a property of the printer. The field in the file header specifies what page height was used for paginating the document. If the page height of the current printer is different, the document has to be re-paginated.
- All sizes are specified in dots, which are 1/80 of an inch on paper, and the same as GEOS screen pixels. geoWrite documents are either 480 (6 inches, “regular”) or 640 (8.2 inches, “wide”) dots wide. The default height (i.e. if no printer is installed) is 752 dots (9.4 inches).
These are the contents of the VLIR records of a geoWrite document:
| Records | Contents |
|---|---|
| 0-60 | Pages |
| 61 | Header |
| 62 | Footer |
| 63 | Reserved |
| 64-126 | Images |
- A document can have up to 61 pages, which are stored in records 0 through 60. Internally, page numbering is zero-based. For the UI, the start page number from the header is added.
- The text for the header and footer are stored in two separate records. They have the same format as pages.
- geoWrite supports up to 63 inline images, each of which is stored in its own record, which is pointed to by the page that contains the image.
In a properly closed geoWrite document, all page records are consecutive with no empty records in between, all image records are referenced by pages, pagination is consistent with the page height in the header, and the header and footer height values in the header correspond to the text in the header and footer records.
Text Format
The text is stored in ASCII format, that is, codes $20 through $7F are printable characters, and codes $00 through $1F are control codes. Of these, only the following are defined:
| Code | Description |
|---|---|
| $00 | No-Op |
| $09 | Tab |
| $0C | Page Break |
| $0D | Line Break |
| $10 | Graphics Escape |
| $11 | Ruler Escape |
| $17 | NewCardSet Escape |
The $00 character code specifies the end of the file. The graphics, ruler and NewCardSet escape codes indicate data structures that need a detailed description.
NewCardSet Escape
The NewCardSet structure encodes a change in font and style. It can appear anywhere in the document.
| Offset | Size | Contents | Description |
|---|---|---|---|
| 0 | Byte | Escape Code | Constant $17 (ESC_NEWCARDSET) |
| 1-2 | Word | Font ID | Encoded font and point size identifier |
| 3 | Byte | Style | Text style bitfield |
- GEOS Font IDs are 16 bit values that encode the unique font identifier (0: system font, 1: University, 2: California, 3: Roma, …) in bits 6-15, and the point size in bits 0-5.
- The style bitfield is defined as follows:
| Bit | Description |
|---|---|
| 7 | Underline |
| 6 | Bold |
| 5 | Reverse |
| 4 | Italics |
| 3 | Outline |
| 2 | Superscript |
| 1 | Subscript |
| 0 | Reserved |
- All bits can be combined, except subscript with superscript.
- All zero bits indicate plain text.
Ruler Escape
The ruler structure encodes a paragraph’s properties. It can appear only at the beginning of a new paragraph.
| Offset | Type | Contents | Description |
|---|---|---|---|
| 0 | Byte | Escape Code | Constant $11 (ESC_RULER) |
| 1-2 | Word | Left Margin | Left margin |
| 3-4 | Word | Right Margin | Right margin |
| 5-6 | Word | Tab Stop 0 | Position/type of tab stop 0 |
| 7-8 | Word | Tab Stop 1 | Position/type of tab stop 1 |
| 9-10 | Word | Tab Stop 2 | Position/type of tab stop 2 |
| 11-12 | Word | Tab Stop 3 | Position/type of tab stop 3 |
| 13-14 | Word | Tab Stop 4 | Position/type of tab stop 4 |
| 15-16 | Word | Tab Stop 5 | Position/type of tab stop 5 |
| 17-18 | Word | Tab Stop 6 | Position/type of tab stop 6 |
| 19-20 | Word | Tab Stop 7 | Position/type of tab stop 7 |
| 21-22 | Word | Paragraph Margin | Left margin of first line of paragraph |
| 23 | Byte | Spacing/Alignment | Line spacing and text alignment |
| 24 | Byte | Reserved | Reserved for text color |
| 25 | Byte | Reserved | Reserved |
| 26 | Byte | Reserved | Reserved |
- All sizes are in dots.
- The left margin is less than the right margin, and the tab stops are in ascending order.
- The most significant bit of each tab stop indicates whether it is a regular or a decimal tab stop. Decimal tab stops align the decimal separator to the tab stop.
| Bit 15 | Description |
|---|---|
| 0 | Regular tab stop |
| 1 | Decimal tab stop |
- Line spacing and alignment are encoded into a single byte:
| Bits 0-1 | Description |
|---|---|
| 0 | Left aligned |
| 1 | Centered |
| 2 | Right aligned |
| 3 | Justified |
| Bits 2-3 | Description |
|---|---|
| 0 | 1.0 line spacing |
| 1 | 1.5 line spacing |
| 2 | 2.0 line spacing |
Graphics Escape
The graphics escape is used to embed an image into the text. It can appear anywhere in the document, and is regarded as a paragraph of its own.
| Offset | Type | Contents | Description |
|---|---|---|---|
| 0 | Byte | Escape Code | Constant $10 (ESC_GRAPHICS) |
| 1 | Byte | Image Width | Width of image divided by 8 |
| 2-3 | Word | Image Height | Height of image |
| 4 | Byte | Record Number | Number of record containing image data |
- All sizes are in dots.
- The width of the image has to be divisible by 8.
- The record number of the image data is in the range of 64 through 126.
Page Format
To divide the linear text into pages, it is not enough to just cut the file at the (hard or soft) page breaks. When navigating to a page, it would not be clear what the current font and paragraph style of the first character of the page should be. Therefore, every page starts with a header containing this information, repeating the font/style/ruler state from the end of the previous page:
| Offset | Length | Contents | Description |
|---|---|---|---|
| 0-26 | 27 Bytes | Ruler Data | Ruler data |
| 27-30 | 4 Bytes | NewCardSet Data | Font/style data |
| 31 | ASCII Text | Text of the document |
The ruler data and NewCardSet data include their respective escape codes (ESC_RULER = $11, ESC_NEWCARDSET = $17), which makes any page by itself legally formatted geoWrite text.
Memory Representation
The strategy of the editor is to basically keep a single page in RAM and editing there. This way, for most editing work, there is no need to access the disk.
The buffer in RAM is 7000 bytes in size and in the same format as a page on disk: The first bytes are the header (ruler, NewCardSet), and the remainder is the actual text data, which may include NewCardSet, ruler and graphics escapes.
When the user jumps to a page, the corresponding record is loaded into the buffer. And when a new page is added to the document, an empty page is created in the buffer.
But the buffer isn’t always exactly one page. The text in the buffer starts at a known page boundary in the document, and the start of the buffer is associated with a page number in the document on disk.
But the amount of text in the buffer may be more than fits on the current page: If the user enters some text in the middle of a page, it will be inserted at the corresponding place in the buffer. The text at the end of the buffer may technically belong to the next page, because when laying out the current page, it wouldn’t fit.
The buffer may also be less than the current page of the document: If the user deletes text from the middle of a page, then the data in the buffer may not fill the current page any more – what should show up at the very bottom of this page is actually stored in the following record.
Streaming
It is not a problem to have more text than fits the page in the buffer (as long as the data doesn’t overflow the available 7000 bytes – we’ll talk about that later). But if there is less than a page in the buffer, and the bottom of the page needs to be rendered onto the screen, the missing text needs to be loaded from the next record.
The whole next record is unlikely to fit into the remainder of the current buffer, so the memory management logic loads data from the following records at a block (256 byte) granularity.
Let’s look at the code that does this. When rendering the page for the screen or for printing, and during re-pagination, all code goes through the getByteFromBuffer function:
getByteFromBuffer:
CmpW pageEndPtr, r15 ; end reached?
bcc @end ; yes
ldy #0
lda (r15),y ; read byte
rts
The virtual register r15 points to the next byte, and pageEndPtr points to the end of the data in the buffer. The interesting case here is reaching the end:
@end: bit streamingMode
bpl @skip
[push r0 though r15]
jsr streamBlock
[pop r0 though r15]
bra getByteFromBuffer ; try again
@skip: lda #0
rts
If streamingMode is false, the function just returns NULL bytes, indicating the end of the buffer. But in “streaming mode”, it calls streamBlock (not shown). On its first invocation, this function manually looks up the next record in the filesystem and loads the first block, appending it to the data in the buffer, basically extending the buffer by a single block from the next record. The getByteFromBuffer code now has more data that it can fetch.
On subsequent invocations, streamBlock will keep reading blocks from the record, and will also skip to the following records. With streamingMode enabled, getByteFromBuffer will effectively read bytes from the whole document linearly.
The ruler and NewCardSet escapes at the beginning of each record are redundant and not needed when concatenating the pages, so streamBlock skips them. All of this is completely transparent to the caller.
Let’s look at an example in practice: The document has two pages of text. The user is at the very top of the first page and deletes a few lines. Visually, a few lines from the second page should now show up at the bottom of the first page. But the editor does not care at this point, the buffer only contains the reduced data. And since the cursor is still at the top of the page (and vertically, only about one fifth of a page fits onto the screen), the text renderer for the screen won’t reach the end of the buffer when reading bytes. But once the user moves the cursor down to the end of the page, the text renderer’s calls to getByteFromBuffer will cause one or more blocks of the next record to be loaded into the buffer before the part can be shown that was previously on page 2.
Reading in blocks from subsequent pages is not just some temporary look-ahead: Even though the read-in blocks still exist on disk as part of the next record, geoWrite now regards the data as part of the buffer in memory and will disregard them when accessing the next record in the future.
Repagination
When adding text to or deleting text from the middle of a document, the document generally needs re-pagination at some point, that is, the document will be updated so that every record on disk contains exactly the text of the corresponding page. geoWrite does this lazily: As seen before, most editing within a page happens on the buffer in memory. The buffer usually only gets written back to disk when moving away from the current page, at which point the remainder if the document needs to be repaginated.
The same is true if the buffer overflows the available 7000 bytes: The document has to be repaginated from the current page on. Every record will only be filled with text for exactly one page, so when the record for the current page will be loaded again afterwards, it should be significantly below 7000 bytes.
Triggers
There are many other actions that trigger a repagination run, like:
- The page height changes because of switching printers or toggling NLQ printing mode.
- The page width is changed from 480 to 640 dots. (geoWrite does not allow switching back.)
- The “title page” setting is toggled. Since this toggles showing the header and footer on the first page, the height of this page that is usable for text changes.
- The header or footer is edited, potentially changing their heights and changing the usable height of pages.
- The search/replace function changes text on arbitrary pages.
- The function update in the file menu explicitly updates the document on disk into a consistent state, which includes repagination.
- The same is done when closing the document or quitting the app.
In some cases, like writing back a page to disk or closing a document, only repagination of pages following the current one is necessary.
Basic Algorithm
The basic repagination algorithm looks like this:
- Read the first page into the buffer and enable
streamingModeforgetByteFromBuffer. Using this function, the whole (remaining) document can now be read as if it was one linear file. - Keep reading from the document until the text fills a page.
- Write the current buffer up to this point (including the header) to the record on disk that corresponds to the current page.
- Move the remaining data in the buffer up to the beginning. This data is the start of the next page.
- Copy the current font, style and ruler state into buffer’s page header.
- Repeat all of this until the end of the data is reached.
Measuring Lines
The core of pagination is the function that measures a line of text. Starting with the current pointer into the buffer, it reads and interprets bytes from the document, and returns the line’s width, height, baseline and a buffer pointer that points to the first character of the next line.
This function is also used for rendering a line on screen or for the printer: Before a line can be rendered, the baseline has to be calculated, so that different fonts on the same line are printed consistently. And the width of the line is necessary to center it, for example.
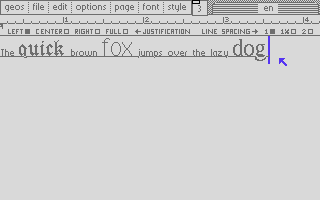
The following screenshot shows an example of mixed fonts in a single line, where it is necessary to gather the lowest baseline before starting to draw the text:
First, this function calculates the available width by subtracting the left margin from the right margin. For the first line of a paragraph, the “paragraph margin” will be used instead of the left margin. It then reads and interprets the document byte by byte.
If a graphics escape is encountered, the height of the image is returned as the line height, since images are always in their own paragraphs.
Otherwise, the function keeps adding up the widths of characters based on the current font, and keeps track of the maximum baseline offset and maximum font height.
A TAB character in the text requires some additional logic: A TAB will have the cursor jump to the next tab stop. To account for this, the measure line function increases the width of the line to reach the tab stop. In the following example, the two words are separated by a TAB character.
tab stop
|
.............*..............
Hello World!
/\/\/\/\
added width
For decimal tab stops, it calculates the widths of all following text until the next decimal separator, and increases the width up to the tab stop minus the width of this text. In the following example, “84” is measured, and enough width is added so that the decimal separator is lined up with the tab stop.
decimal tab stop
|
.............*..............
Total 84.25 EUR
/\/\/\
added width
If there is a ruler escape in the text, the ruler data gets copied into the app’s state. All further calculations will use the new margins and tab stops. The same happens for NewCardSet escapes: All further character size calculations will be based on the new font and style.
During repagination, the metrics of all fonts used in the particular part of the document need to be known to be able to add up character widths. The geoWrite font manager has a font metrics cache that can hold data for up to 8 fonts, which is more than the font data cache, which can only hold an average of 3 font images, depending on their size. The font files have to be loaded at least once in order to extract the metrics, but the images are not necessary for repagination, and it is enough to keep the metrics data.
The end of a line is reached once the text overflows the available width. The function will then reset the buffer pointer to after the last SPACE character – this is the first character of the new line.
The end of a line is also reached if there is either an explicit line break or page break in the text. In this case, the pointer will be set to the character after the break.
Measuring Pages
The function that measures a page first calculates the usable height by subtracting the header and footer heights from the page height – unless this is the title page, in which the full page height is available.
It then repeatedly calls the function to measure a line and adds up line heights until the sum overflows the usable page height. The buffer pointer is reset to the beginning of the first line that does not fit onto the page. This is the first character of the next page.
A special case is the page break character: Page measuring is stopped here, and the pointer to the next character is returned.
Conclusion
While geoWrite is extremely powerful for an app on a 1 MHz computer with 64 KB of RAM, it is also very slow. Some of the reasons are true for many GEOS applications:
- The 6502 cannot efficiently handle 16 bit data, so dealing with pointers and dot size values requires large and slow code everywhere.
- Because of memory scarcity, code has to repeatedly be paged in for certain functionality.
- Some of the code is especially inefficient, because it had to be optimized for size rather than for speed.
- Even with the GEOS “turboDisk” driver, the 1541 disk drive is still very slow, at a maximum of 4 KB/sec of linear reading.
In this context, geoWrite picked a document model that allows the user to edit a page at a time practically without any disk access, with the tradeoff of slower repagination. So in practice, repaginating a document that contains dozens of pages can take a minute or more, but on the other hand, geoWrite can usually keep up with the fastest typists when rendering even complicated text layouts in real-time.
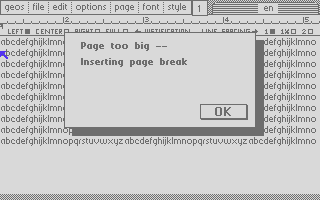
P.S.: The image at the beginning of this article shows the error message caused by a record overflowing 7000 bytes. This happens when using a font that is 9 pt or smaller and filling a page completely with characters. geoWrite will insert a page break character and re-run the pagination code.