Emu8080: an HTML5 App to Emulate a Complete CP/M Machine
by Stefan Tramm
Some Assembly Required
by Stefan Tramm
Modern filesystems are highly optimized database systems that are a core function of modern operating systems. They allow concurrent access by many CPUs, they keep locality up and fragementation down, and they can recover from crashes guaranteeing consistent data structures.
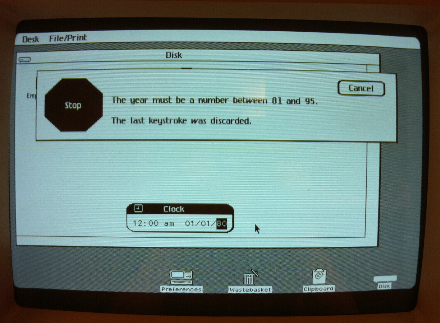
If you try to set the clock in Lisa OS 3.1 to 2010, you’re out of luck:

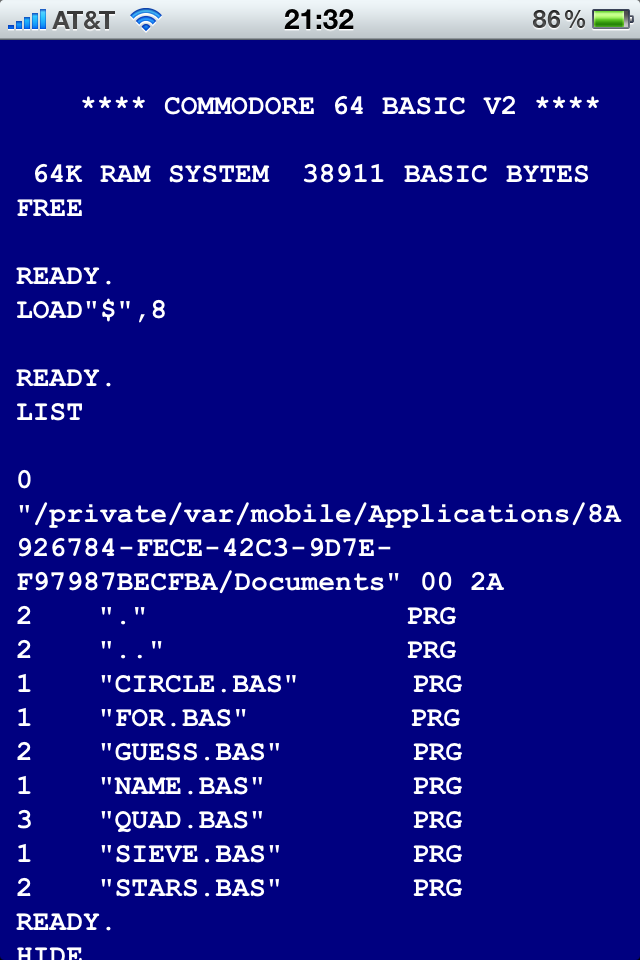
You might remember the hassle about the Commodore 64 emulator in the iPhone App Store about a year ago: First it was approved, but then pulled again, because it allowed access to the C64’s BASIC – general-purpose interpreters were not allowed. After Apple relaxed this restriction, BASIC was added again.
After 35 years of measuring the behaviour of the MOS 6502 CPU to better understand what is going on, the Visual6502 simulator finally allows us insight into the chip, so we can understand what the CPU does internally. One interesting thing here is the question how the 6502 handles BRK, IRQ, NMI and RESET.
The MOS 6502 CPU was introduced in September of 1975, and while the documentation described the three shift/rotate instructions ASL, LSR and ROL, the ROR instruction was missing – the documentation said that ROR would be available in chips starting in June 1976. In fact, the reason for this omission was that the instruction, while being present, didn’t behave correctly. Only few 6502s with the defect are in existence, and nobody seemed to have checked what was actually going on in these chips.
Everything can be expressed in bits. It takes 4 kilobits to decompress ZIP data, 25 kilobits to kill a human, 43 megabits for a working Mac OS X kernel, and 10^120 bits to describe our universe. What is the entropy/complexity of the 6502 CPU, you might wonder?
A while ago, an engineer from a respectable company for low-level solutions (no names without necessity!) claimed that a certain company’s new 4-way SMP system had broken CPUs or at least broken firmware that didn’t set up some CPU features correctly: While on the older 2-way system, all CPUs returned the same features (using CPUID), on the 4-way system, two of the CPUs would return bogus data.
In the talk “Why Silicon Security is still that hard” by Felix Domke at the 24th Chaos Communication Congress in 2007 (in which he described how he hacked the Xbox 360, and bushing had a cameo at the end explaining how they hacked the Wii), I had a little part, in which I argued that “Linux Is Inevitable”: If you lock down a system, it will eventually get hacked. In the light of the recent events happening with PlayStation 3 hacking, let’s revisit them.
If you want to enable protected mode or paging on the i386/x86_64 architecture, you use CR0, which is short for control register 0. Makes sense. These are important system settings. But if you want to switch the pagetable format, you have to change a bit in CR4 (CR1 does not exist and CR2 and CR3 don’t hold control bits), if you want to switch to 64 bit mode, you have to change a bit in an MSR, oh, and if you want to turn on single stepping, that’s actually in your FLAGS. Also, have I mentioned that CR5 through CR15 don’t exist – except for CR8, of course?

The MOS KIM-1 is a quite rare collector’s item today. So if you hold one in your hands, you better take some high resolution pictures of the board. Here they are:

There is only one way to find out – all you need is a giant pile of money and a vending machine that sells soda for $1.25: If you put in a dollar note and press the “return change” button, you will get the dollar note back directly. If you put in two dollar notes (the maximum it takes) at a time, it will give you change for the two dollars.
I understand that there might be a good reason for Intel to add virtualization extensions to their CPU architecture. Instead of fixing the x86 architecture to (optionally) make it Popek-Goldberg compliant and have all critial instructions trap if not run in Ring 0, they added non-root mode, a very big hammer that allows me to switch my CPU state completely to that of the guest and switches back to my original host state on a certain event in the guest. Well, it’s a great toy for people who want to play with CPU internals.
Google is always right.
Here is a fun game for long car rides: One person names a respected standard implemented by dozens of IT companies, and the other person names Microsoft’s competing technology. Example: MPEG Audio (MP3/AAC) – Windows Media Audio.
I am sitting here, working with my PC: My keyboard and my mouse are connected wirelessly via Bluetooth and my monitor is hooked up through DVI. The graphics card is sitting in a PCI slot, main memory is DDR-SDRAM, and my optical drive can do CDs and DVDs. While my internal hard disk speaks the SATA protocol, my home directory is actually sitting on an SD card that is connected through a USB reader. My internet connection is done through DSL. On the software side, I am using GNU/Linux and browsing the internet with Firefox. No way I would ever watch a video in H.264 format.

I just did a Lightning Talk at the 26th Chaos Communication Congress 26C3 about our new project “libcpu”, and it has already been picked up by Golem.de and reddit.com, so I might as well announce it here: