Digitizing Analog Video through a Digital Camcorder
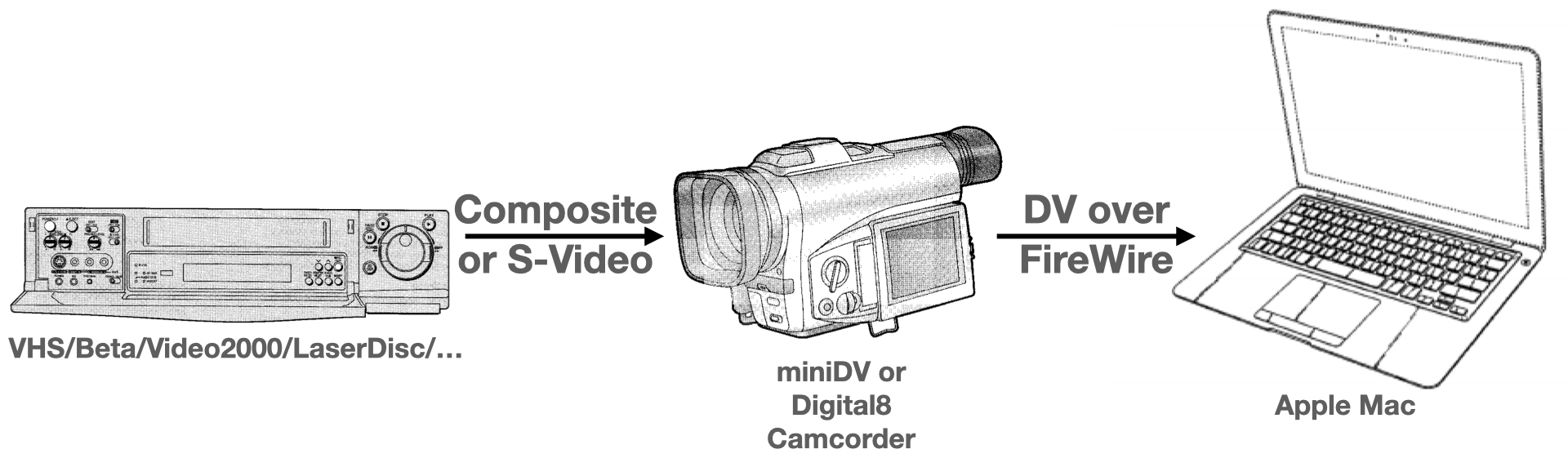
This article explains a setup and workflow for digitizing analog video (e.g. VHS, Beta, Video 2000, LaserDisc, …) using a Mac and digital camcorder – in high quality and with interlacing intact; optimized for archival. We will use a old-school digital camcorder (they are cheap!) to convert the analog signal to a high-quality digital “DV” stream and then record the DV stream on a Mac using a FireWire connection.
Comparing BitTorrent Downloads of Interlaced TV Shows
In my previous blog post, I was comparing how internet video providers like Hulu, Netflix, iTunes, Amazon and Zune handle interlaced material by comparing an episode of Futurama. This time, let’s see how rips from the BitTorrent network compare to these.
Comparing Digital Video Downloads of Interlaced TV Shows

In the days of CRT monitors, TV shows used to be broadcast in interlaced mode, which is unsupported by modern flat-panel displays. All online streaming services and video stores provide progressive video, so they must deinterlace the data first. This article compares the deinterlacing strategies of Apple iTunes, Netflix, Microsoft Zune, Amazon VoD and Hulu by comparing their respective encodings of a Futurama episode.