64'er Magazin – mit 40 Jahren Verzögerung jetzt monatlich im Web
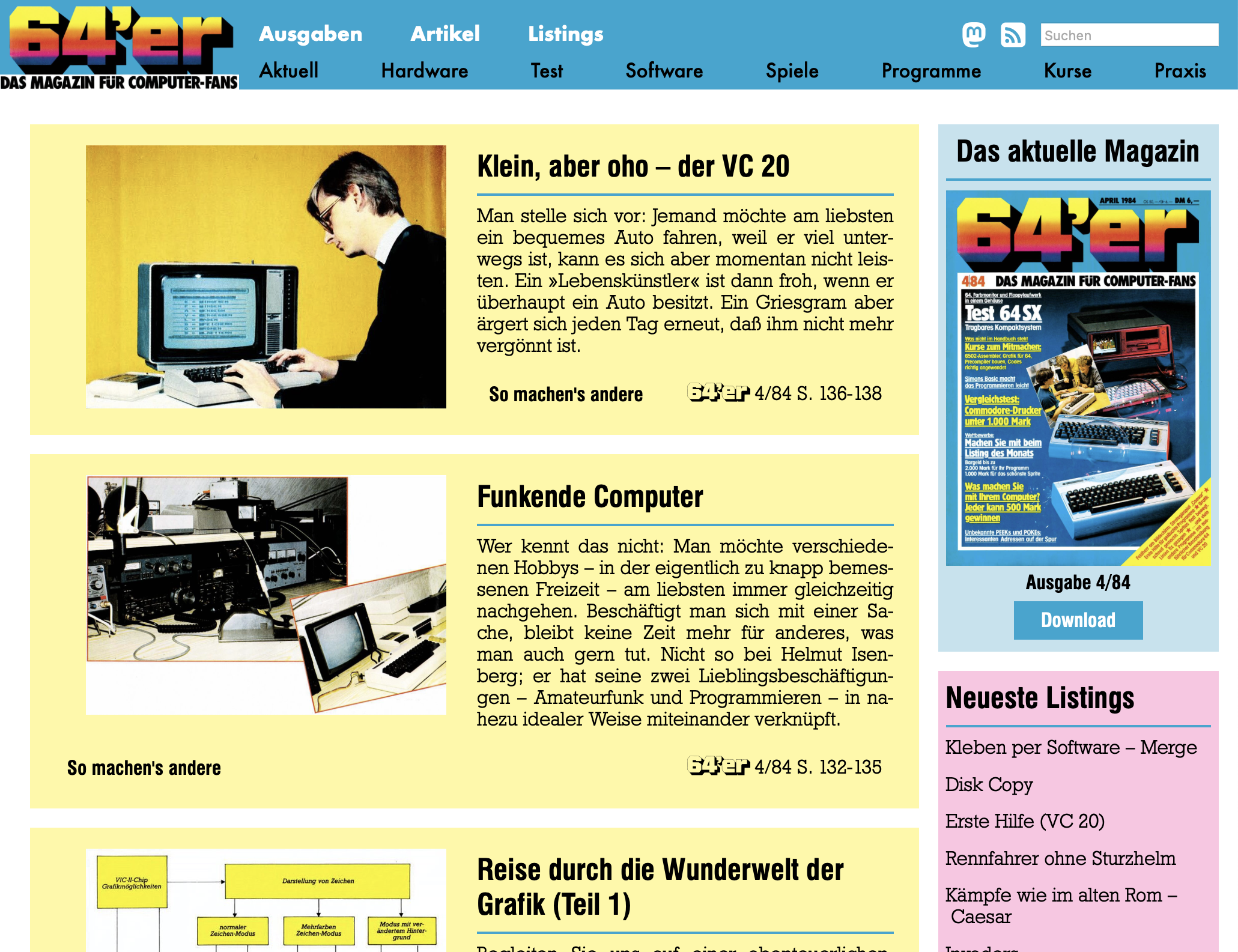
Zum 40jährigen Jubiläum des 64’er Magazins präsentieren wir das Kunstprojekt www.64er-magazin.de: eine Website, die so tut, als wäre 1984. Exakt 40 Jahre nach der ursprünglichen Veröffentlichung erscheint hier jeden Monat eine neue Ausgabe:
Silo S01E06: 38911 BYTES FREE

[Ankündigung] Vortrag “Apollo Guidance Computer” an der Embedded Computing Conference in Winterthur

This post is about an upcoming talk in German.
The Easter Egg in the “Schrott-Tornado” at the Deutsches Museum

The Deutsches Museum in Munich (Germany) has a new art installation as part of the reopened Electronics exhibition: The “Schrott-Tornado”, a tornado-shaped sculpture made from scrap electronics. There is (at least) one item in it that is most definitely not trash.
darmok.com: Memes in the Tamarian Language

I have created darmok.com, a website that lets you share common memes in the Tamarian language.
PostScript Cartridge for HP LaserJet

We have recently dissected and dumped the Level 2 “Plus” version of HP’s PostScript cartridge series. This time, we will look at the earlier Level 1 “PostScript Cartridge”.
Scanntronik Manuals

The German company “Scanntronik” offered a lot of high-quality hardware and software for the Commodore 64 series computers, most in the space of graphics and desktop publishing. They are well-known for their Pagefox and Printfox software as well as their Handyscanner 64 hardware. This page offers most of the German-language manuals from across their product range as searchable PDFs.
The Commodore AUTOMODEM (Model 1650)

The Commodore 1650, also known as the “AUTOMODEM”, is Commodore’s first full modem directly connected to the phone line. It supports pulse dialing in software and 300 baud duplex connections.
A 1960s Children's Book about Computers

The 1963 book “Robots and Electronic Brains” (by Robert Scharff) from the “How and Why Wonder Books” series is an early children’s book about computers. Let’s look at some of the interesting contents – and how the German translation “Was ist was: Roboter und Elektronengehirne” from 1967 changed some details.
Digitizing Analog Video through a Digital Camcorder
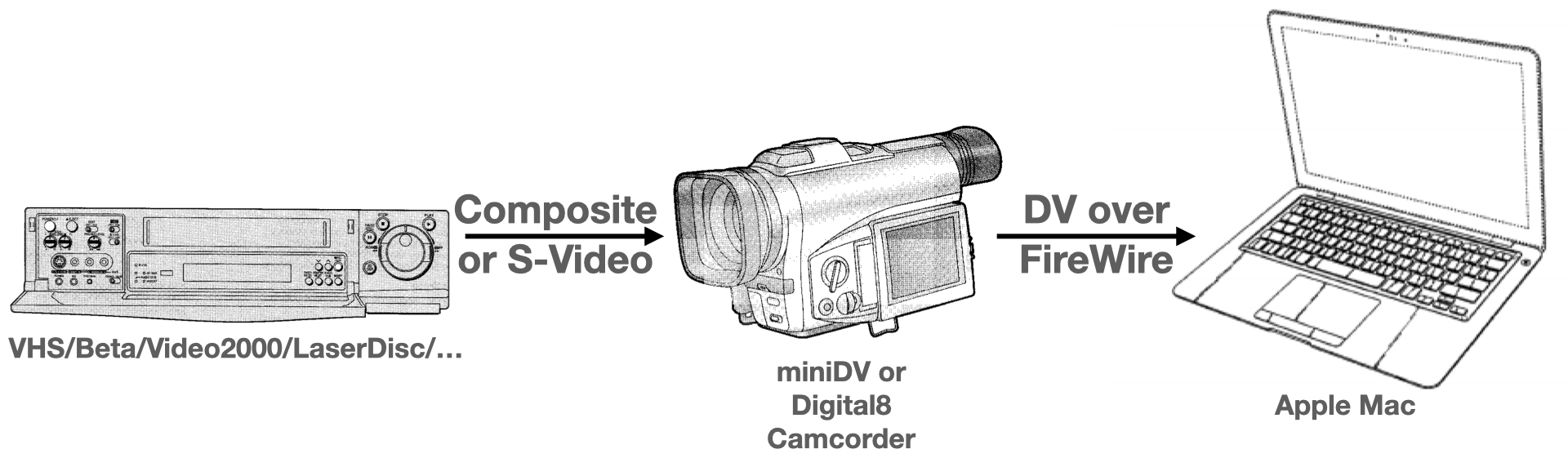
This article explains a setup and workflow for digitizing analog video (e.g. VHS, Beta, Video 2000, LaserDisc, …) using a Mac and digital camcorder – in high quality and with interlacing intact; optimized for archival. We will use a old-school digital camcorder (they are cheap!) to convert the analog signal to a high-quality digital “DV” stream and then record the DV stream on a Mac using a FireWire connection.
Dissecting a Dummy Promo MiniDisc

Many pre-recorded MiniDiscs are rare and expensive. An extra rare special case is the dummy promo copy of Michael Jackson’s “Dangerous”, which we will dissect in this article.
The Commodore VICMODEM (Model 1600)

The Commodore 1600, also known as the “VICMODEM”, is Commodore’s very first modem (1982): It supports 300 baud duplex connections, and is connected to an existing telephone’s handset connector instead of the phone line. This kept the price down, but required the user to dial manually through the phone.
PostScript Cartridge Plus for HP LaserJet III

The HP LaserJet III laser printer from 1990 used the “Printer Command Language” PCL 5 by default, but could be upgraded with the “HP PostScript Cartridge Plus” cartridge, which contained 2 MB of ROM with Adobe’s PostScript Level 2 rasterizer. Let’s look at the ROM contents and some of its hidden gems.
CCGMS Future 0.2
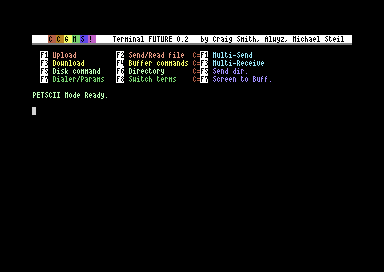
CCGMS Future 0.2 was just released. It adds 80 columns support, a true ASCII charset (in 80c mode), and bug fixes.
The Punter C1 Protocol
The Punter file transfer protocol (“New Punter”/“Punter C1”) is an alternative to the XMODEM family of protocols, which was and still is very popular on BBSes for Commodore computers. It is notorious for being badly documented. Let’s fix that.
UP9600: How to Bit-Bang 9600 Baud RS-232 on the C64
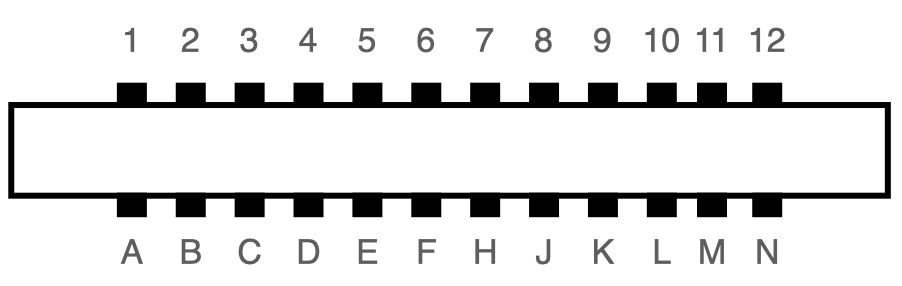
The user port of the Commodore 64 exposes a TTL-level RS-232 serial port that supports up to 1200 baud1. In 1997, Daniel Dallmann came up with a very sophisticated trick that allowed sending and receiving at 9600 baud2, using slightly different wiring and a dedicated driver. This “UP9600” wiring has become the de-facto standard for all modern accessories, like C64 WiFi modems. Let’s see how UP9600 works.
The Commodore Modem/1200 (Model 1670)

The Commodore 1670, also known as the “Modem/1200”, is Commodore’s first Hayes-compatible modem: It connects directly to the phone line and supports pulse and tone dialing for 1200 and 300 baud duplex connections. There were two revisions, the original 1670 and the “new” 1670, a.k.a. CR-1670. (The unit in this article is the later revision.)
The Commodore Modem/300 (Model 1660)

The Commodore 1660, also known as the “Modem/300”, is Commodore’s first full-featured modem: It connects directly to the phone line and supports pulse and tone dialing for 300 baud duplex connections.
Announcing CCGMS Future 0.1
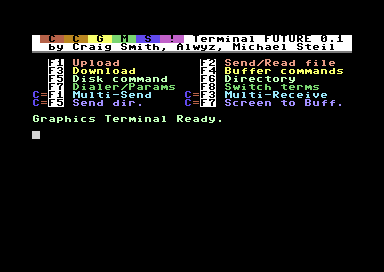
The CCGMS Terminal Program for the Commodore 64 is maintained again, and there is a new version: CCGMS Future 0.1, with bug fixes and new features.
Free Joystick Extension Cable to Build Your DB9 Competition Pro

This article explains how to convert a “Competition Pro Extra USB” (which you can still buy new) to work with a C64, Amiga or Atari. For the conversion, you need a joystick extension cable like this: