In Windows Vista x64, drivers are required to be signed by someone holding a VeriSign code certificate or they won’t load. There is no way to (permanently) disable this signing even if you are Administrator. The F8 startup menu has an option to disable it, but you must select it every time you boot up. Microsoft’s claimed reason for this is that it prevents Trojans from installing kernel-mode rootkits. That is a load of crap.
Racism in Monstropolis

Sometimes, freezeframe fun does not provide fun, but sadness.
Leave security to security code. Or: Stop fixing bugs to make your software secure!
If you read about operating system security, it seems to be all about how many holes are discovered and how quickly they are fixed. If you look inside an OS vendor, you see lots of code auditing taking place. This assumes all security holes can be found and fixed, and that they can be eliminated more quickly that new ones are added. Stop fixing bugs already, and take security seriously!
Comparing Digital Video Downloads of Interlaced TV Shows

In the days of CRT monitors, TV shows used to be broadcast in interlaced mode, which is unsupported by modern flat-panel displays. All online streaming services and video stores provide progressive video, so they must deinterlace the data first. This article compares the deinterlacing strategies of Apple iTunes, Netflix, Microsoft Zune, Amazon VoD and Hulu by comparing their respective encodings of a Futurama episode.
The Intel 80376 – a Legacy-Free i386 (with a Twist!)
25 years after the introduction of the 32 bit Intel i386 CPU, all Intel compatibles still start up (and wake up!) in 16 bit stone-age mode, and they have to be switched into 32/64 bit mode to be usable.
For Lisa, the World Ended in 1995
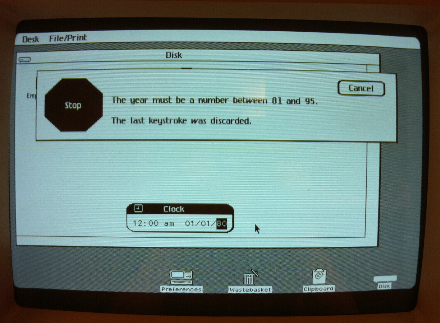
If you try to set the clock in Lisa OS 3.1 to 2010, you’re out of luck:
Name that Ware

CPUID on all CPUs (HOWNOTTO)
A while ago, an engineer from a respectable company for low-level solutions (no names without necessity!) claimed that a certain company’s new 4-way SMP system had broken CPUs or at least broken firmware that didn’t set up some CPU features correctly: While on the older 2-way system, all CPUs returned the same features (using CPUID), on the 4-way system, two of the CPUs would return bogus data.
Why is there no CR1 – and why are control registers such a mess anyway?
If you want to enable protected mode or paging on the i386/x86_64 architecture, you use CR0, which is short for control register 0. Makes sense. These are important system settings. But if you want to switch the pagetable format, you have to change a bit in CR4 (CR1 does not exist and CR2 and CR3 don’t hold control bits), if you want to switch to 64 bit mode, you have to change a bit in an MSR, oh, and if you want to turn on single stepping, that’s actually in your FLAGS. Also, have I mentioned that CR5 through CR15 don’t exist – except for CR8, of course?
Intel VT VMCS Layout
I understand that there might be a good reason for Intel to add virtualization extensions to their CPU architecture. Instead of fixing the x86 architecture to (optionally) make it Popek-Goldberg compliant and have all critial instructions trap if not run in Ring 0, they added non-root mode, a very big hammer that allows me to switch my CPU state completely to that of the guest and switches back to my original host state on a certain event in the guest. Well, it’s a great toy for people who want to play with CPU internals.
PCEPTPDPTE
Here is a new pagetable entry.
Building the Solaris Kernel in 73 Easy Steps
Everyone and their grandmother builds Linux kernels. Many people build BSD, and some brave men even compile the OS X kernel every now and then. Why not compile your own Solaris kernel for a change?
Black Hat letdown
I went to Black Hat over Wednesday and Thursday. The presentation most people wanted to see (including me) was Joanna Rutkowska breaking the Vista x64 driver signing that I hate so much. I wanted to see what trick she’d found. I was let down, however, when she presented her technique.
Redundant SSE instructions
As we all know the x86-ISA has a lot of redundant instructions (ie. instructions with the same semantic but different opcodes). Sometimes this is unavoidable, sometimes it looks like bad design. But with SSE it gets really weird. Let’s say we want to perform xmm0 <- xmm0 & xmm1 (ie. bitwise and). Not an uncommon operation; but we have 3 different ways do archive this:
- andps xmm0, xmm1 (0f 54 c1)
- andpd xmm0, xmm1 (66 0f 54 c1)
- pand xmm0, xmm1 (66 0f db c1)
(Note that andpd/pand are SSE2 instructions)
Regarding the result in xmm0 these are really the same instructions. Now, why did Intel do this? First we’re going to inspect andps/andpd. Looking at the optimization manuals we get a hint: The ps/pd mark the target register to contain singles or doubles, so they should match the actual data you are operating on.
Virtualization: The elegant way and the x86 way
Virtualization means running one or more complete operating systems (at the same time) on one machine, possibly on top of another operating system. VMware, VirtualPC, Parallels etc. support, for example, running a complete GNU/Linux OS on top of Windows. For virtualization, the Virtual Machine Monitor (VMM) must be more powerful than kernel mode code of the guest: The guest’s kernel mode code must not be allowed to change the global state of the machine, but may not notice that its attempts fail, as it was designed for kernel mode. The VMM as the arbiter must be able to control the guest completely.
Microsoft changes CS value in Win64
I just found out the hard way that in 32 bit programs under Win64, the value of CS changed. In Win32, the value of CS is 0x001B. In 32 bit programs under Win64, it’s 0x0023. This will probably break some programs, especially debuggers.