darmok.com: Memes in the Tamarian Language

I have created darmok.com, a website that lets you share common memes in the Tamarian language.
Inside geoWrite – 3: Font Management
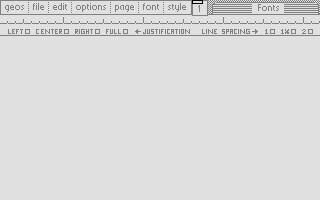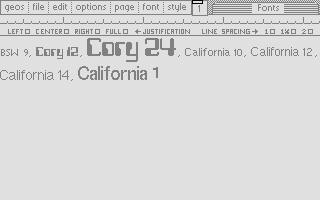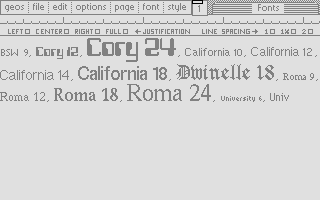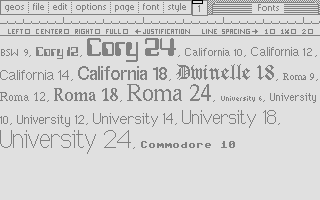
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses the font manager’s system of caches for pixel fonts.
The Double Inverted Inconsistency Principle
In a discussion, when pointing out inconsistencies in your opponent’s opinion by giving two examples that you disagree with, remember that it can be made into a point against you, just by inverting the two examples – plus/minus some rhetorical decoration.
Windows Phone 7 & the Floppy Disk
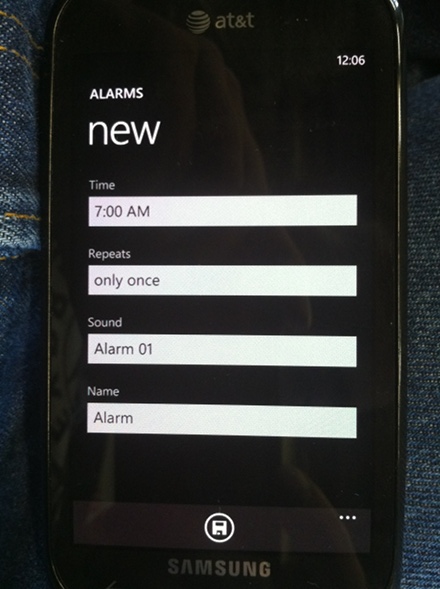
I’m sure all users will immediately associate a Sony 3.5″ Floppy Disk with “save”. It’s not like the stock icon library also had an OK button.
Standards and Intellectual Property
I am sitting here, working with my PC: My keyboard and my mouse are connected wirelessly via Bluetooth and my monitor is hooked up through DVI. The graphics card is sitting in a PCI slot, main memory is DDR-SDRAM, and my optical drive can do CDs and DVDs. While my internal hard disk speaks the SATA protocol, my home directory is actually sitting on an SD card that is connected through a USB reader. My internet connection is done through DSL. On the software side, I am using GNU/Linux and browsing the internet with Firefox. No way I would ever watch a video in H.264 format.
Buggy Drivers

Announcement: ‘libcpu’ Binary Translator
I just did a Lightning Talk at the 26th Chaos Communication Congress 26C3 about our new project “libcpu”, and it has already been picked up by Golem.de and reddit.com, so I might as well announce it here: