How the Final Cartridge III Freezer works
by Daniël Mantione
Final Cartridge III with GEOS

The Final Cartridge III is great: It comes with a disk speeder, BASIC extensions, an excellent monitor – and an impressive, but ultimately useless GUI, because there are practically no applications for it. Let’s replace the FC3 GUI with GEOS!
Illegal Opcode Support for the Final Cartridge III Monitor

The monitor built into the Final Cartridge III is one of the best ones for the C64. Some of its unique features are:
Final Cartridge III Monitor for the TED

In my quest to make the C16 more usable, i.e. more like the environment I’m used to, i.e. a C64 with a Final Cartridge III, I’ve ported the Final Cartridge III monitor to the TED series (C16, C116, Plus/4).
Reverse-Engineered Final Cartridge III Source Code
The Final Cartridge III was one of the major multi-function extension cartridges for the Commodore 64. It contained BASIC extensions, floppy and tape speeders, centronics printer support, screen editor extensions including F-key shortcuts, a monitor, a freezer – and a GEOS-like windowing system called “Desktop”. In all this, the FC3 integrated seamlessly with the look-and-feel of the stock Commodore 64: It did not change anything (same screen colors and banner!), it only extended functionality in consistent ways.
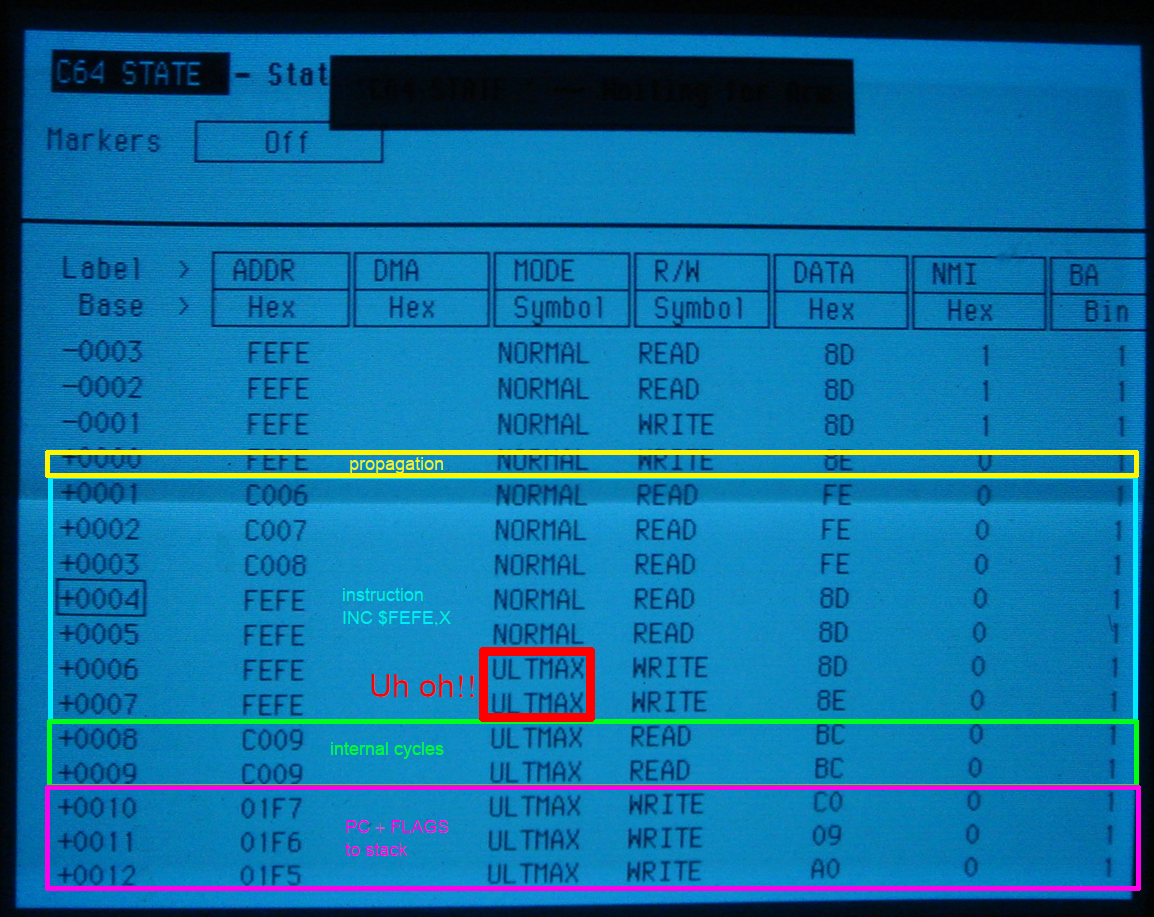
Final Cartridge III Undocumented Functions
The “Final Cartridge III” has been among the most popular Commodore 64 extensions, providing a floppy speeder, BASIC extensions, a machine language monior, a freezer and even a (rarely used) graphical desktop. The major advantage compared to other C64 cartridges is the consistent way in which the Final Cartridge III extends the C64 experience.