64’er Magazin 5/84
Die Ausgabe 5/84 ist nun auf www.64er-magazin.de verfügbar. Vielen Dank an goloMAK, Endurion und Drachen für das Abtippen der Listings!
Some Assembly Required
Die Ausgabe 5/84 ist nun auf www.64er-magazin.de verfügbar. Vielen Dank an goloMAK, Endurion und Drachen für das Abtippen der Listings!
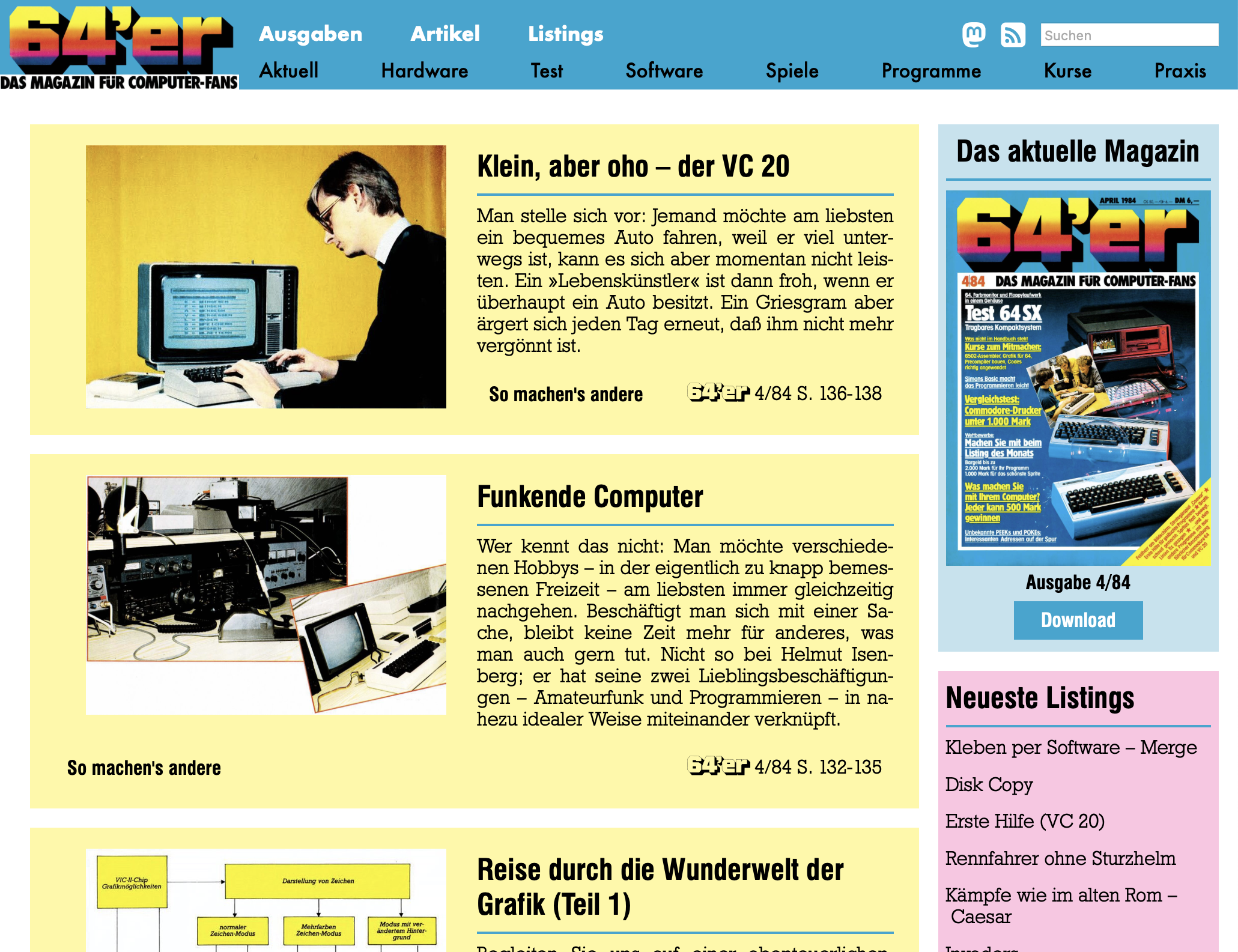
Zum 40jährigen Jubiläum des 64’er Magazins präsentieren wir das Kunstprojekt www.64er-magazin.de: eine Website, die so tut, als wäre 1984. Exakt 40 Jahre nach der ursprünglichen Veröffentlichung erscheint hier jeden Monat eine neue Ausgabe:

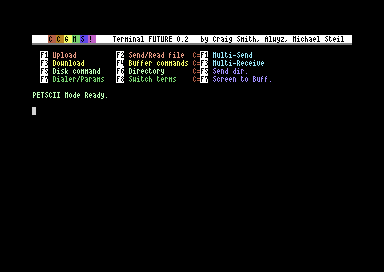
CCGMS Future 0.2 was just released. It adds 80 columns support, a true ASCII charset (in 80c mode), and bug fixes.
The Punter file transfer protocol (“New Punter”/“Punter C1”) is an alternative to the XMODEM family of protocols, which was and still is very popular on BBSes for Commodore computers. It is notorious for being badly documented. Let’s fix that.
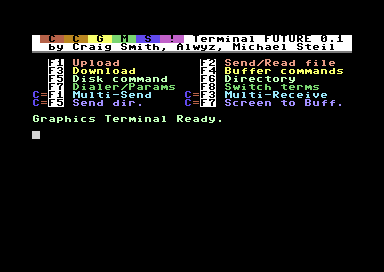
The CCGMS Terminal Program for the Commodore 64 is maintained again, and there is a new version: CCGMS Future 0.1, with bug fixes and new features.
This is the video recording of “The Ultimate Commodore 1541 Disk Drive Talk” at VCF West 2021. As always, if you think it’s too fast, try watching it at 0.75x speed!

After
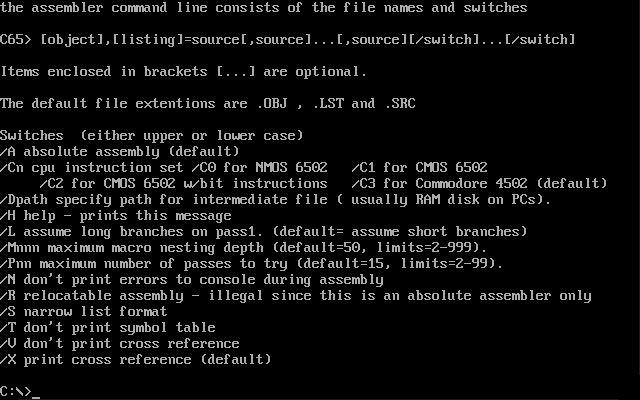
In the series about the assemblers Commodore used for developing the ROMs of their 8-bit computers, this article covers the 1989 “Commodore 6502 Assembler” (6502ASM), a cross-assembler written in C that ran on VAX and PC.
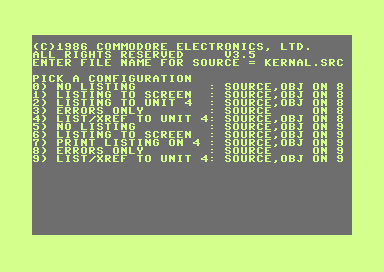
In the series about the assemblers Commodore used for developing the ROMs of their 8-bit computers, this article covers the 1987 “HCD65” assembler that ran on the C128.
In the series about the assemblers Commodore used for developing the ROMs of their 8-bit computers, this article covers the 1984 “Boston Systems Office” (BSO) cross-assembler running on VAX/VMS.
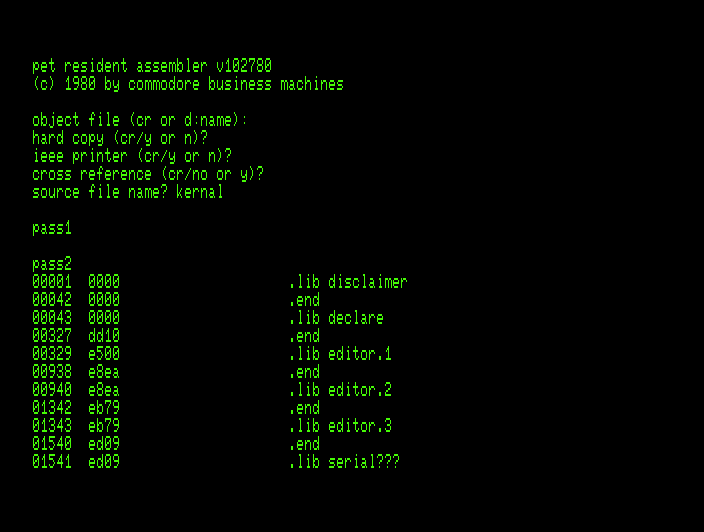
In the series about the assemblers Commodore used for developing the ROMs of their 8-bit computers, this article covers the 1976 “MOS Resident Assembler” that ran on a variety of 6502-based computers.
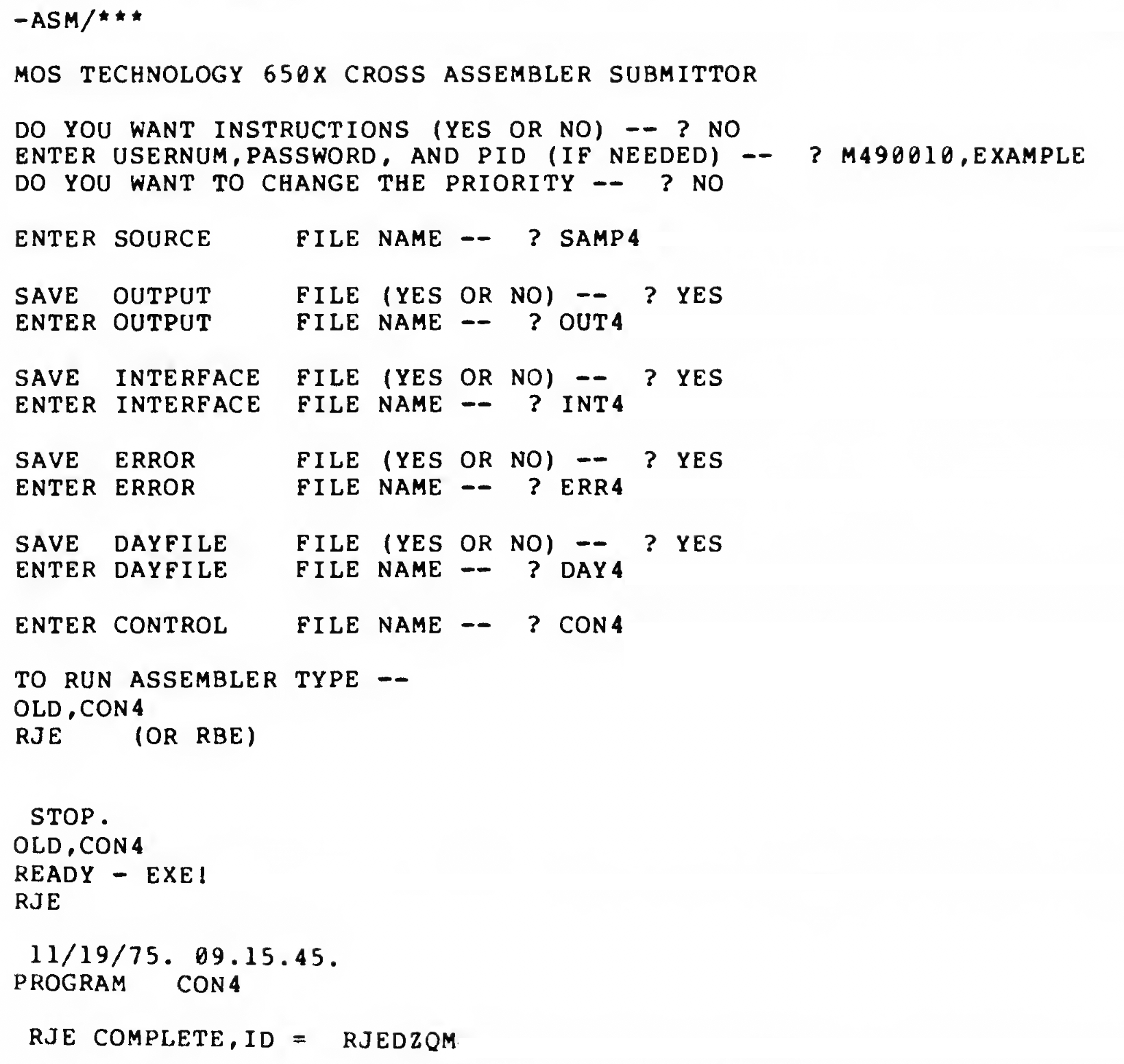
In the series about the assemblers Commodore used for developing the ROMs of their 8-bit computers, this article covers the 1975 “MOS Cross-Assembler”, which was available for various mainfraimes of the era.
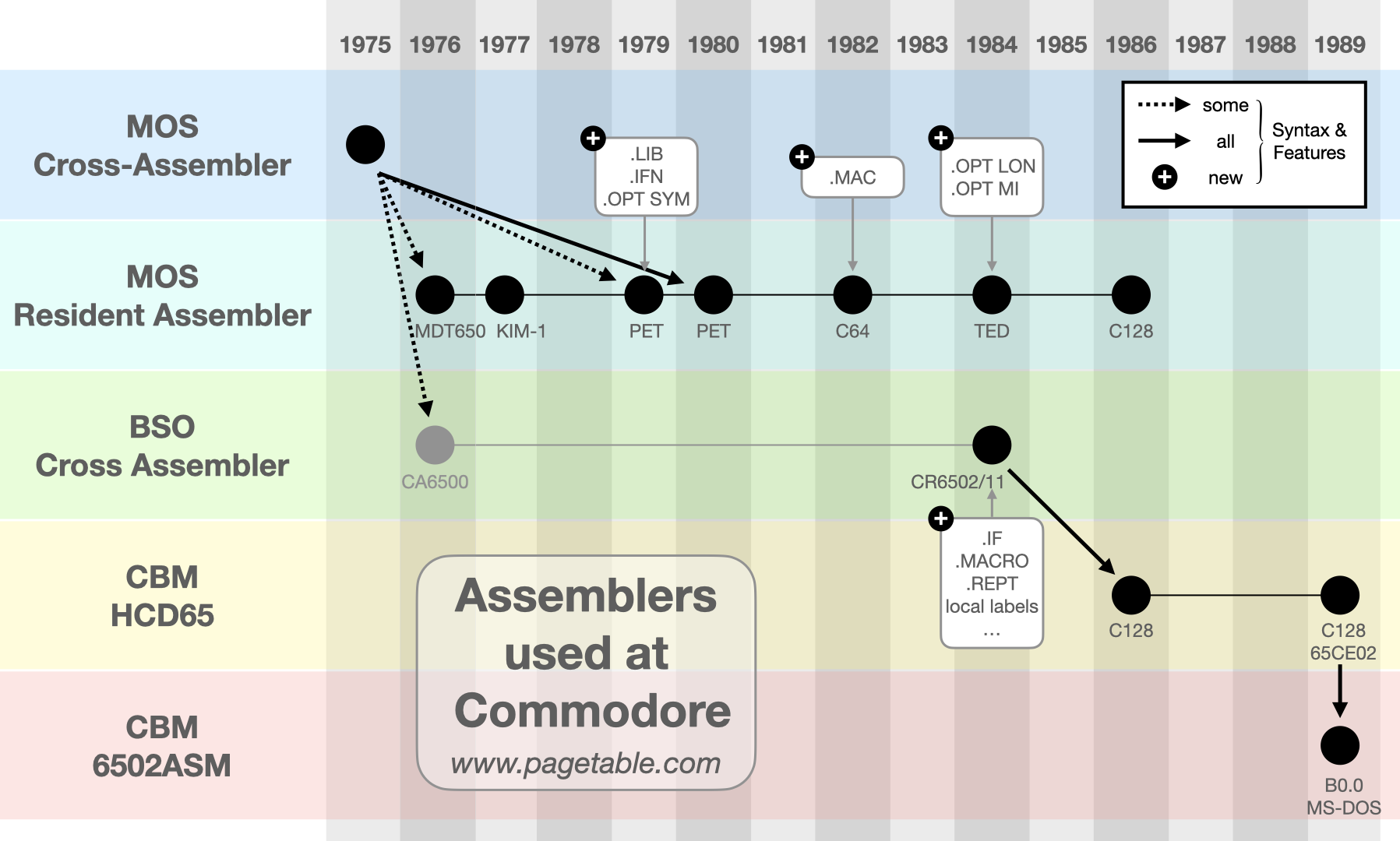
Commodore used 5 different assemblers, most of them in-house tools, to build the ROMs for their Computers like the PET, the C64 and the C128. Nevertheless, all Commodore source files, from 1975 to 1990, share a common format and use the same assembly directives. This series of articles describes each of these assemblers.
geoWrite is a WYSIWYG rich text editor for the Commodore 64 GEOS operating system. I created a reverse-engineered source version of the geoWrite 2.1 for the C64 (English and German) for the cc65 compiler suite:

This post is about an upcoming talk in German.

In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses how the app consolidates keyboard input to keep up with fast typists.
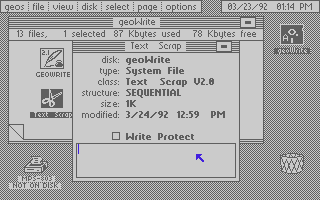
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses its efficient cross-application cut/copy/paste implementation.
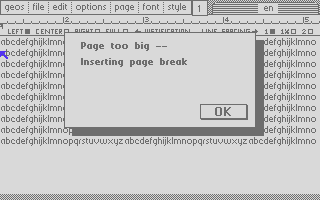
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses how its file format allows the app to efficiently edit documents hundreds of KB in size.