[Ankündigung] Vortrag “Apollo Guidance Computer” an der Embedded Computing Conference in Winterthur

This post is about an upcoming talk in German.
The Easter Egg in the “Schrott-Tornado” at the Deutsches Museum

The Deutsches Museum in Munich (Germany) has a new art installation as part of the reopened Electronics exhibition: The “Schrott-Tornado”, a tornado-shaped sculpture made from scrap electronics. There is (at least) one item in it that is most definitely not trash.
PostScript Cartridge for HP LaserJet

We have recently dissected and dumped the Level 2 “Plus” version of HP’s PostScript cartridge series. This time, we will look at the earlier Level 1 “PostScript Cartridge”.
The Commodore AUTOMODEM (Model 1650)

The Commodore 1650, also known as the “AUTOMODEM”, is Commodore’s first full modem directly connected to the phone line. It supports pulse dialing in software and 300 baud duplex connections.
A 1960s Children’s Book about Computers

The 1963 book “Robots and Electronic Brains” (by Robert Scharff) from the “How and Why Wonder Books” series is an early children’s book about computers. Let’s look at some of the interesting contents – and how the German translation “Was ist was: Roboter und Elektronengehirne” from 1967 changed some details.
Digitizing Analog Video through a Digital Camcorder
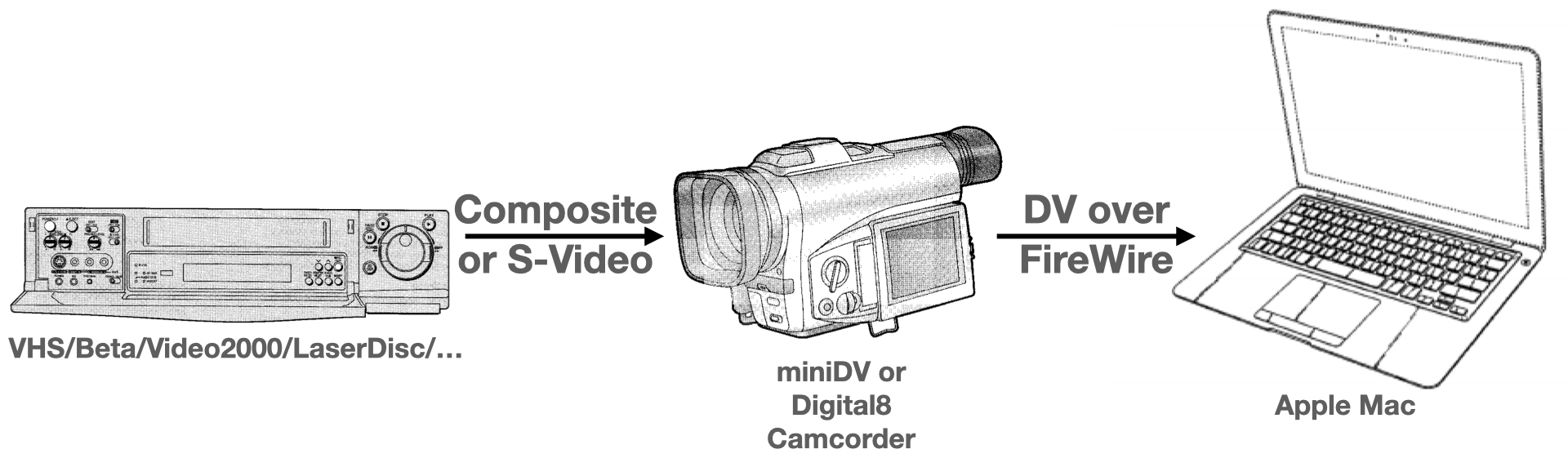
This article explains a setup and workflow for digitizing analog video (e.g. VHS, Beta, Video 2000, LaserDisc, …) using a Mac and digital camcorder – in high quality and with interlacing intact; optimized for archival. We will use a old-school digital camcorder (they are cheap!) to convert the analog signal to a high-quality digital “DV” stream and then record the DV stream on a Mac using a FireWire connection.
Dissecting a Dummy Promo MiniDisc

Many pre-recorded MiniDiscs are rare and expensive. An extra rare special case is the dummy promo copy of Michael Jackson’s “Dangerous”, which we will dissect in this article.
The Commodore VICMODEM (Model 1600)

The Commodore 1600, also known as the “VICMODEM”, is Commodore’s very first modem (1982): It supports 300 baud duplex connections, and is connected to an existing telephone’s handset connector instead of the phone line. This kept the price down, but required the user to dial manually through the phone.
PostScript Cartridge Plus for HP LaserJet III

The HP LaserJet III laser printer from 1990 used the “Printer Command Language” PCL 5 by default, but could be upgraded with the “HP PostScript Cartridge Plus” cartridge, which contained 2 MB of ROM with Adobe’s PostScript Level 2 rasterizer. Let’s look at the ROM contents and some of its hidden gems.
The Punter C1 Protocol
The Punter file transfer protocol (“New Punter”/“Punter C1”) is an alternative to the XMODEM family of protocols, which was and still is very popular on BBSes for Commodore computers. It is notorious for being badly documented. Let’s fix that.
The Commodore Modem/1200 (Model 1670)

The Commodore 1670, also known as the “Modem/1200”, is Commodore’s first Hayes-compatible modem: It connects directly to the phone line and supports pulse and tone dialing for 1200 and 300 baud duplex connections. There were two revisions, the original 1670 and the “new” 1670, a.k.a. CR-1670. (The unit in this article is the later revision.)
The Commodore Modem/300 (Model 1660)

The Commodore 1660, also known as the “Modem/300”, is Commodore’s first full-featured modem: It connects directly to the phone line and supports pulse and tone dialing for 300 baud duplex connections.
The Ultimate Commodore 1541 Disk Drive Talk [video]
This is the video recording of “The Ultimate Commodore 1541 Disk Drive Talk” at VCF West 2021. As always, if you think it’s too fast, try watching it at 0.75x speed!
Reverse-Engineered geoWrite 2.1 for C64 Source Code
geoWrite is a WYSIWYG rich text editor for the Commodore 64 GEOS operating system. I created a reverse-engineered source version of the geoWrite 2.1 for the C64 (English and German) for the cc65 compiler suite:
Inside geoWrite – 9: Keyboard Handling

In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses how the app consolidates keyboard input to keep up with fast typists.
Inside geoWrite – 8: Copy & Paste
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses its efficient cross-application cut/copy/paste implementation.
Inside geoWrite – 7: File Format and Pagination
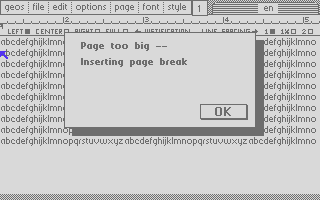
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses how its file format allows the app to efficiently edit documents hundreds of KB in size.
Inside geoWrite – 6: Localization
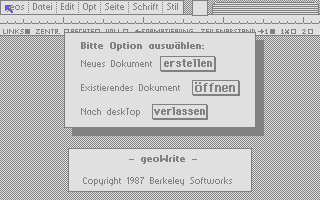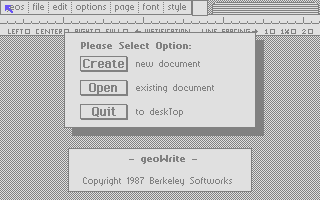
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses what was required for the German localization.
Inside geoWrite – 5: Copy Protection
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses the geoWrite copy protection.
Inside geoWrite – 4: Zero Page
In the series about the internals of the geoWrite WYSIWYG text editor for the C64, this article discusses how it makes maximum use of the scarce zero page space.